# 📚 编程范式
编程范式有两种,分别是命令式(Imperative)和声明式(Declarative),命令式强调做的步骤也就是怎么做,而声明式强调做什么本身,以及做的结果。
因此,编程语言也可以分成命令式和声明式两种类型,如果再细分的话,命令式又可以分成过程式和面向对象,而声明式则可以分成逻辑式和函数式。下面这张图列出了编程语言的分类和每个类型下经典的编程语言。
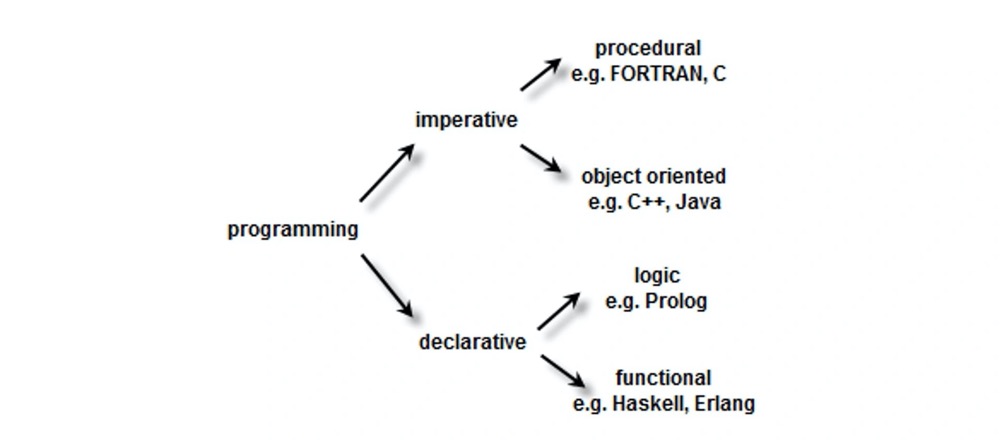
可以看到,图中并没有 JavaScript,实际上 JavaScript 同时拥有命令式和声明式的特征,因此开发者可以同时用 JavaScript 写出命令式与声明式风格的代码。
比如要遍历一个数组,将每一个元素的数值翻倍,我们可以分别用命令式和声明式来实现。
// 命令式的实现代码
let list = [1, 2, 3, 4];
let map1 = [];
for(let i = 0; i < list.length; i++){
map1.push(list[i] * 2);
}
2
3
4
5
6
7
// 声明式的实现代码
let list = [1, 2, 3, 4];
const double = x => x * 2;
list.map(double);
2
3
4
# 📚 函数式编程思维
函数式编程是数学的概念,写函数式编程的时候脑子里想的是数学里的函数,而不是 JavaScript 里的函数。因此,函数式编程实际上就是把数学的思维带到了开发中。
# 📘 范畴论(Category Theory)
函数式编程是范畴论的数学分支,是一门很复杂的数学,认为世界上所有概念体系都可以抽象成一个个范畴。
彼此之间存在某种关系的概念、事物、对象等等,都构成范畴。任何事物只要找出他们之间的关系,就能定义范畴。
箭头表示范畴成员之间的关系,正式的名称叫作 “态射”。
范畴论认为,同一个范畴的所有成员,就是不同状态的 “变形”。通过 “态射”,一个成员可以变形成另一个成员。
范畴的内容包含两点:
(1)所有成员是一个集合。
(2)变形关系是函数。
# 📘 函数式编程基础理论
- 数学中的函数书写形式如右:
f(x) = y。一个函数 f,以 x 作为参数,并返回输出 y。虽然这个概念很简单,但是其中包含几个关键点:
函数必须总是接受一个参数。
函数必须返回一个值。
函数应该依据接收到的参数而不是外部环境运行。
对于给定的 x 只会输出唯一的 y。
函数式编程不是用函数来编程,也不是传统的面向过程编程。它的主旨在于将复杂的函数复合成简单的函数(计算理论、递归论或者拉达姆演算)。运算过程尽量写成一系列的函数嵌套。
通俗的写法是
function xx() {}。要区分开函数和方法,方法要与指定的对象绑定,而函数可以直接调用。函数式编程(Functional Programming)其实相对于计算机的历史而言是一个非常古老的概念,甚至早于第一台计算机的诞生。函数式编程的基础模型来源于 λ(Lambda) 演算(即拉达姆演算),而 λ 演算并非设计于在计算机上执行,它是在 20 世纪三十年代引入的一套用于研究函数定义、函数应用和递归的形式系统。
JavaScript 是披着 C 外衣的 Lisp (opens new window)。Lisp 是一种纯函数式编程的语言。
函数式编程真正的火热是随着 React 的高阶函数而逐步升温的。
函数是一等公民。所谓 “第一等公民”(first class),指的是函数与其他数据类型一样,处于平等地位,可以赋值给其它变量,也可以作为参数,传入另一个函数,或者作为别的函数的返回值。
不可改变量:我们通常理解的变量在函数式编程中也被函数替代了,在函数式编程中变量仅仅代表某个表达式。这里所说的变量是不能被修改的,所有的变量只能被赋一次初值。函数式编程里的值全部是靠传递的,不能改它。函数式编程最讲究的就是纯!
map和reduce是函数式编程最常用的方法。
牢记以下几点
函数是 “第一等公民”
只用 “表达式”,不用 “语句”
没有 “副作用”
不修改状态
引用透明(函数运行只靠参数且相同的输入总是获得相同的输出),比如
identity = (i) { return i },这里调用 identity(1) 的效果可以直接替换为 1,该过程被称为替换模型。
# 📚 函数式编程核心概念
# 📘 函数和纯函数
函数是对过程的封装,但函数的实现本身可能依赖外部环境,或者有副作用(Side-effect)。
所谓函数的副作用,是指函数执行本身对外部环境的改变。我们把不依赖外部环境和没有副作用的函数叫做纯函数,依赖外部环境或有副作用的函数叫做非纯函数。
// add 是一个纯函数,它的返回结果只依赖于输入的参数,与调用的次数、次序、时机等等均无关
function add(x, y) {
return x + y;
}
// getEl 是一个非纯函数,它的返回值除了依赖于参数 id,还和外部环境(文档的 DOM 结构)有关
function getEl(id) {
return document.getElementById(id);
}
// join 也是一个非纯函数,它的副作用是会改变输入参数对象本身的内容,
// 所以它的调用次数、次序和时机不同,我们得到的结果也不同
funciton join(arr1, arr2) {
arr1.push(...arr2);
return arr1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
对于相同的输入,纯函数永远会得到相同的输出,而且没有任何可观察的副作用,也不依赖外部环境的状态。比如 slice 是纯函数,但是 splice 不是纯函数。
在实际开发过程中我们没法保证所有的函数都很纯,但是要明白我们的目标就是让函数尽量的纯。
# 📘 纯函数的优点
纯函数与非纯函数相比,有三个非常大的优点,分别是易于测试(上下文无关)、可并行计算(时序无关)、有良好的 Bug 自限性。
# 1. 易于测试
纯函数易于测试,在用单元测试框架的时候,因为纯函数不需要依赖外部环境,所以我们直接写一个简单的测试 case 就可以了。而非纯函数因为比较依赖外部环境,在测试的时候我们还需要构建外部环境。
# 2. 可并行计算
纯函数可以并行计算。在浏览器中,我们可以利用 Worker 来并行执行多个纯函数,在 Node.js 中,我们也可以用 Cluster 来实现同样的并行执行,而使用 WebGL 的时候,纯函数有时候还可以转换为 Shader 代码,利用 GPU 的特性来进行计算。
# 3. 有良好的 Bug 自限性
因为纯函数不会依赖和改变外部环境,所以它产生的 Bug 不会扩散到系统的其他部分。而非纯函数,尤其是有副作用的非纯函数,在产生 Bug 后,因为 Bug 可能意外改变了外部环境,所以问题会扩散到系统其他部分。这样在调试的时候,就算发现了 Bug,我们可能也找不到真正导致 Bug 的原因,这就给系统的维护和 Bug 追踪带来困难。
总而言之,我们设计系统的时候,要尽可能多设计纯函数,少设计非纯函数,这样能够有效提升系统的可测试性、性能优化空间以及系统的可维护性。
# 📘 函数式编程范式与纯函数
我们该如何让系统的纯函数尽可能多,非纯函数尽可能少呢?答案是用函数式编程范式。下面通过一个例子来说明下。
假设我们要实现一个模块,用它来操作 DOM 中列表元素,改变元素的文字颜色,具体的实现代码如下:
function setColor(el, color) {
el.style.color = color;
}
function setColors(els, color) {
els.forEach(el => setColor(el, color));
}
2
3
4
5
6
7
这个模块中有两个方法,其中 setColor 是操作一个 DOM 元素,改变它的文字颜色,而 setColors 则是批量操作若干个 DOM 元素,改变所有元素的颜色。
尽管这两个方法都非常简单,但它们都改变了外部环境(DOM)所以它们是两个非纯函数。因此,我们在做系统测试的时候,两个方法都需要构建外部环境来实现测试。
如果想让系统测试更简单,我们就可以采用函数式编程思想,把非纯函数的个数减少成一个。
我们可以实现一个 batch 函数来优化。batch 函数接受的参数是一个函数 f,就会返回一个新的函数。在这个过程中,我们要遵循的调用规则是,如果这个参数有 length 属性,我们就以数组来遍历这个参数,用每一个元素迭代 f,否则直接用当前调用参数来调用 f 就可以了。
function batch(fn) {
return function(target, ...args) {
if (target.length >= 0) {
return Array.from(target).map(item => fn.apply(this, [item, ...args]));
} else {
return fn.apply(this, [target, ...args]);
}
}
}
2
3
4
5
6
7
8
9
这里 batch 函数的参数和返回值都是函数,这样的函数叫做高阶函数 (High Order Function)。高阶函数虽然看上去复杂,但它实际上就是一个纯函数。它的执行结果只依赖于参数(传入的函数),与外部环境无关。
我们可以测试一下这个 batch 函数的正确性,方法十分简单只要用下面这个 Case 就行了。
test(t => {
let add = (x, y) => x + y;
let listAdd = batch(add);
t.deepEqual(listAdd([1,2,3], 1), [2,3,4]);
});
2
3
4
5
6
有了 batch 函数之后,我们的模块也可以减少为一个非纯函数。
function setColor(el, color) {
el.style.color = color;
}
let setColors = batch(setColor);
2
3
4
5
# 📘 高阶函数与函数装饰器
所谓高阶函数,是指输入参数是函数,或者返回值是函数的函数。
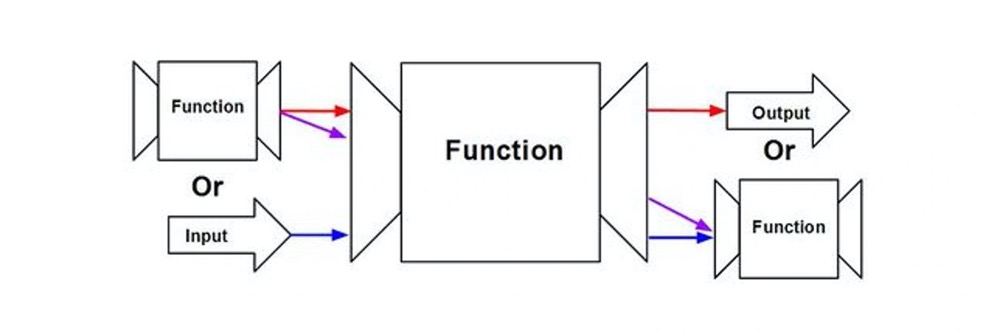
如果输入参数和返回值都是函数,这样的高阶函数又叫做函数装饰器(Function Decorators)。当一个高阶函数是用来修饰函数本身的,它就是函数装饰器。也就是说,它是在原始函数上增加了某些带有辅助功能的函数。
下面通过一个例子来说明下这两者。
假设,我们的代码库要进行大版本升级,在未来最新的版本中我们想要废弃掉某些 API,由于很多业务中使用了老版本的库,不可能一次升级完,因此我们需要做一个平缓过渡。具体来说就是在当前这个版本中,先不取消这些旧的 API,而是给它们增加一个提示信息,告诉调用它们的用户,这些 API 将会在下一次升级中被废弃。
如果我们手工修改要废弃的 API 代码,这会是一件非常繁琐的事情。而且,我们很容易遗漏或者弄错些什么,从而产生不可预料的 Bug。
所以,一个比较聪明的办法是,我们实现一个通用的函数装饰器。
function deprecate(fn, oldApi, newApi) {
const message = `The ${oldApi} is deprecated.
Please use the ${newApi} instead.`;
return function(...args) {
console.warn(message);
return fn.apply(this, args);
}
}
2
3
4
5
6
7
8
9
然后,在模块导出 API 的时候,对需要废弃的方法统一应用这个装饰器。
// deprecation.js
// 引入要废弃的 API
import {foo, bar} from './foo';
// ...
// 用高阶函数修饰
const _foo = deprecate(foo, 'foo', 'newFoo');
const _bar = deprecate(bar, 'bar', 'newBar');
// 重新导出修饰过的API
export {
foo: _foo,
bar: _bar,
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这样,我们就利用函数装饰器,无侵入地修改了模块的 API,将要废弃的模块用 deprecate 包装之后再输出,就实现了我们想要的效果。这里,我们实现的 deprecate 就是一个纯函数,它的维护和使用都非常简单。
# 📘 过程抽象
function parametric(xFunc, yFunc) {
return function (start, end, seg = 100, ...args) {
const points = [];
for(let i = 0; i <= seg; i++) {
const p = i / seg;
const t = start * (1 - p) + end * p;
const x = xFunc(t, ...args); // 计算参数方程组的 x
const y = yFunc(t, ...args); // 计算参数方程组的 y
points.push([x, y]);
}
return {
draw: draw.bind(null, points),
points,
};
};
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
可以看出,parametric 是一个高阶函数,它比上面的函数装饰器更加复杂一点的是,它的输入是两个函数 xFunc 和 yFunc,输出也是一个函数,返回的这个函数实际上是一个过程,这个过程是对 x、y 的参数方程根据变量 t 的值进行采样。
实际上 parametric 函数封装的是一个过程,这种封装过程的思路,叫做过程抽象。前面的函数装饰器,还有 batch 方法,实际上也是过程抽象。对应的一般程序设计中我们不是封装过程,而是封装数据,所以叫做数据抽象。
过程抽象是函数式编程的基础,函数式编程对待函数就像对待数据一样,都会进行封装和抽象,这样能够设计出非常通用的功能模块。
# 📘 纯度和幂等性
幂等性是指执行无数次后还具有相同的效果,同一的参数运行一次函数应该与连续运行两次的结果一致。
幂等性在函数式编程中与纯度相关,但又不一致。
Math.abs(Math.abs(-42));
# 📘 偏应用函数
// 偏应用函数的参数是一个函数和该函数的部分参数
const partial = (f, ...args) =>
(...moreArgs) =>
f(...args, moreArgs)
2
3
4
比如:
const add3 = (a, b, c) => a + b + c
// 偏应用2、3到 add3
const fivePlus = partial(add3, 2, 3);
fivePlus(4);
// bind 实现,就是偏应用函数的一种实现
const add1More = add3.bind(null, 2, 3); // add1More(c) => 2 + 3 + c
2
3
4
5
6
7
8
# 📘 函数的柯里化
柯里化(Curry)通过偏应用函数实现。它是把一个多参数的函数转换为一个嵌套一元函数的过程。
传递给函数一部分参数来调用它,让它去处理剩下的参数。
var checkage = min => (age => age > min);
var checkage18 = checkage(18);
checkage18(20);
2
3
- 柯里化的优点
柯里化不仅能够解决纯函数的硬编码问题,事实上柯里化还是一种 “预加载” 函数的方法,通过传递较少的参数,得到一个已经记住了这些参数的新函数,某种意义上来讲,这是一种对参数的 “缓存”,是一种非常高效的编写函数的方法。
import { curry } from 'lodash';
var match = curry((reg, str) => str.match(reg));
var filter = curry((f, arr) => arr.filter(f));
var haveSpace = match(/\s+g/);
haveSpace('fffffff');
haveSpace('a b');
filter(haveSpace, ['abcdefg', 'Hello World']);
filter(haveSpace)(['abcdefg', 'Hello World']);
2
3
4
5
6
7
8
9
10
11
function foo(p1, p2) {
this.val = p1 + p2;
}
var bar = foo.bind(null, 'p1');
var baz = new bar('p2');
console.log(baz.val);
2
3
4
5
6
# 📘 函数的反柯里化
- 函数的柯里化,是固定部分参数,返回一个接受剩余参数的函数,也称为部分计算函数,目的是为了缩小适用范围,创建一个针对性更强的函数。
// 柯里化之前
function add(x, y) {
return x + y;
}
add(1, 2); // 3
// 柯里化之后
function addX(y) {
return function(x) {
return x + y;
}
}
addX(2)(1); // 3
2
3
4
5
6
7
8
9
10
11
12
13
// 手写一个柯里化函数
const curry = (fn, arr = []) =>
(...args) =>
(arg => (arg.length === fn.length ? fn(...arg) : curry(fn, arg)))([...arr, ...args])
let curryTest = curry((a, b, c, d) => a + b + c + d);
curryTest(1, 2, 3)(4); // 10
curryTest(1, 2)(3)(4); // 10
curryTest(1, 2)(3, 4); // 10
2
3
4
5
6
7
8
9
- 反柯里化函数,从字面上看,意义和用法跟函数柯里化正好相反,目的是扩大适用范围,创建一个应用范围更广的函数。使得原本只有特定对象才适用的方法,扩展到更多的对象。
// 手写一个反柯里化函数
Function.prototype.unCurring = function() {
var that = this;
return function() {
var obj = Array.prototype.shift.call(arguments);
return that.apply(obj, arguments);
}
}
var push = Array.prototype.push.unCurring(), obj = {};
push(obj, 'first', 'two');
console.log(obj);
2
3
4
5
6
7
8
9
10
11
# 📘 柯里化和偏应用的区别
- 柯里化的参数列表是从左向右的。如果使用 setTimeout 这种就得额外的封装。
const setTimeoutWrapper = (timeout, fn) => {
setTimeout(fn, timeout);
}
const delayTenMs = _.curry(setTimeoutWrapper)(10);
delayTenMs(() => console.log('Do x Task'));
delayTenMs(() => console.log('Do y Task'));
2
3
4
5
6
在这段代码中,setTimeoutWrapper 显得多余,这时候我们就可以用偏应用函数。使用 Curry 和 Partial 都是为了让函数参数或函数设置变得更加简单和强大。
- Curry 和 Partial 的实现可以参考 lodash (opens new window)。
# 📘 函数组合
- 纯函数以及如何把它柯里化会写出洋葱🧅代码
h(g(f(x))),为了解决函数嵌套的问题,我们需要用到函数组合。
const compose = (f, g) => (x => f(g(x)));
const first = arr => arr[0];
const reverse = arr => arr.reverse();
const getLast = compose(first, reverse);
getLast([1, 2, 3, 4, 5]); // 5
2
3
4
5
- 函数组合让函数之间的调用更加灵活。
compose(f, compose(g, h));
compose(compose(f, g), h);
compose(f, g, h);
2
3
# 📘 函数组合子
compose 函数只能组合接收一个参数的函数,类似 map、filter 这些接收两个参数的函数(也叫投影函数:总是在应用里做转换操作,通过传入高阶参数后返回数组),不能被直接组合。可以借助偏函数包裹后继续组合。
函数组合的数据流是从右至左的,因为最右边的函数首先被执行,然后将数据传递给下一个,以此类推。但是有人喜欢让最左边的先执行,我们可以实现 pipe(可称为管道、序列)来实现。它和 compose 函数所做的事情一样,只不过交换了数据方向。
因此我们需要组合子管理程序的控制流。
组合子可以组合其他函数(或其他组合子),并作为控制逻辑单元的高阶函数,组合子通常不声明任何变量,也不包含任何业务逻辑,它们旨在管理函数程序执行流程,并在链式调用中对中间结果进行操作。
常见的组合子
(1)辅助组合子
无为(nothing)、照旧(identity)、默许(defaultTo)、恒定(always)
(2)函数组合子
收缩(gather)、展开(spread)、颠倒(reverse)、左偏(partial)、右偏(partialRight)、柯里化(curry)、弃离(tap)、交替(alt)、补救(tryCatch)、同时(seq)、聚集(converge)、映射(map)、分捡(useWith)、规约(reduce)、组合(compose)
(3)谓语组合子
过滤(filter)、分组(group)、排序(sort)
(4)其它
组合子变换 juxt
以上组合子分属于 SKI 组合子。
lodash 里的所有方法实际上用的就是组合子的概念,它们都是为了帮你控制程序的执行流程。
# 📘 Point Free
- 把一些对象自带的方法转化成纯函数,不要命名转瞬即逝的中间变量。比如:
const f = str => str.toUpperCase().split('');
这个函数中,我们使用了 str 作为我们的中间变量,但是这个中间变量除了让代码变得长一点之外毫无意义。
采用 Point Free 风格改造下:
var toUpperCase = word => word.toUpperCase();
var split = x => (str => str.split(x));
var f = compose(split(''), toUpperCase);
f('abcd efgh');
2
3
4
5
6
这种风格能够帮我们减少不必要的命名,让代码保持简洁和通用。
# 📘 声明式与命令式代码
命令式代码就是,我们通过编写一条又一条指令让计算机执行一些动作,这其中一般都会涉及到很多繁杂的细节。
声明式代码就要优雅很多了,我们通过编写表达式的方式来声明我们想干什么,而不是通过一步一步的指示。
// 命令式
let CEOs = [];
for (let i = 0; i < companies.length; i++) {
CEOs.push(companies[i].CEO);
}
// 声明式
let CEOs = companies.map(c => c.CEO);
2
3
4
5
6
7
8
- 优缺点
(1)函数式编程的一个明显的好处就是这种声明式的代码,对于无副作用的纯函数,我们完全可以不考虑函数内部是如何实现的,专注于编写业务代码。优化代码时,目光只需要集中在这些稳固的函数内部即可。
(2)相反,不纯的函数代码会产生副作用或者依赖外部系统环境,使用它们的时候总是要考虑这些不干净的副作用。在复杂的系统中,这对程序员的心智来说是极大的负担。
# 📘 类 SQL 数据:函数即数据
select p.firstname from persons p where ... group by ...
_mixin({
'select': _.pluck,
'from': _.chain,
'where': _.filter,
'groupby': _.sortByOrder
})
const persons = {};
_.from(persons).where().select().value();
2
3
4
5
6
7
8
9
10
以函数形式对数据建模,也就是函数即数据。声明式的描述了数据输出是什么,而不是数据是如何得到的。
# 📘 惰性链、惰性求值、惰性函数
_.chain(data).map().reverse().value()
- 惰性链可以添加一个输入对象的状态,从而能够将这些输入转换为所需的输出操作链接在一起。与简单的数组操作不一样,尽管它是一个复杂的程序,但仍然可以避免创建任何变量,并且有效消除所有循环。而且在最后调用 value 之前并不会真正的执行任何操作。这就是所谓的惰性链。
// _.chain 可以推断可优化点,如合并执行或存储优化
// 合并函数执行并压缩计算过程中使用的临时数据结构,降低内存占用
const trace = msg => console.log(msg);
let square = x => Math.pow(x, 2);
let isEven = x => x % 2 === 0;
// 使用组合子跟踪
square = R.compose(R.tap(() => trace('map 数组')), square);
isEven = R.compose(R.tap(() => trace('filter 数组')), isEven);
const numbers = _.range(200);
const result = _.chain(numbers)
.map(square)
.filter(isEven)
.take(3)
.value();
console.log(result);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- 当输入很大但只有一个小的子集有效时,避免不必要的函数调用就是所谓的惰性求值。惰性求值方法有很多,如组合子(alt,类似于 ||,先计算 fun1,如果返回值是 false、null、undefined,就不再执行func2),但是目的都是一样的,即尽可能的推迟求值,直到依赖的表达式被调用。
const alt = _.curry((func1, fun2, val) => fun1(val) || fun2(val));
const showStudent = _.compose(函数体1, alt(xx1, xx2));
showStudent({});
2
3
var object = {a: 'xx', b: 2};
var values = _.memoize(_.values);
values(object);
object.a = 'hello';
console.log(values.cache.get(object)); // ["xx", 2]
2
3
4
5
- 惰性函数很好理解,假如同一个函数被大量范围调用,并且这个函数内部又有许多判断来检测函数,这样对于一个调用会浪费时间和浏览器资源,所以当第一次调用完成后,直接把这个函数改写,不再需要判断。
// 判断浏览器的 Ajax 对象
function createXHR() {
var xhr = null;
if (typeof XMLHttpRequest !== 'undefined') {
xhr = new XMLHttpRequest();
createXHR = function() {
return XMLHttpRequest(); // 直接返回一个懒函数,这样没必要再往下走
}
} else {
try {
xhr = new ActiveXObject('Msxml2.XMLHTTP');
createXHR = function() {
return new ActiveXObject('Msxml2.XMLHTTP');
}
} catch(e) {
try {
xhr = new ActiveXObject('Microsoft.XMLHTTP');
createXHR = function() {
return new ActiveXObject('Microsoft.XMLHTTP');
}
} catch(e) {
createXHR = function() {
return null;
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 📘 尾调用优化
尾调用是指函数内部的最后一个动作是函数调用。该调用的返回值,直接返回给函数。
函数调用自身,称为递归。如果尾调用自身,称为尾递归。
递归需要保存大量的调用记录,很容易发生栈溢出错误。如果使用尾递归优化,将递归变为循环,那么只需要保存一个调用记录,这样就不会发生栈溢出错误了。
// 不是尾递归,无法优化斐波那契数列
function factorial(n) {
if (n === 1) return 1;
return n * factorial(n - 1);
}
2
3
4
5
// 尾递归
function factorial(n ,total) {
if (n === 1) return total;
return factorial(n - 1, n * total);
}
2
3
4
5
注意
并不是说尾递归一定不会爆栈,只是不容易爆栈。
浏览器之所以不支持尾递归,是因为会丢失堆栈信息。如果浏览器开启了,那么就只会显示最后一步调用,之前的都会隐藏掉,因此就无法追踪到堆栈信息。
强制开启尾递归的方式有3种:
return continue
!return
#function()
2
3
尾递归的判断标准是函数运行的最后一步是否调用自身,而不是是否在函数的最后一行调用自身。最后一行调用其它函数并返回叫作<font。 color=red>尾调用。
尾递归调用栈永远都是更新当前的栈帧而已,这样就避免了爆栈的危险。但是如今的浏览器并未完全支持,原因有二:
I. 在引擎层面消除递归是一个隐式的行为,程序员意识不到。
II. 堆栈信息丢失了,开发者难以调试。
既然浏览器不支持,我们可以把这些递归写成
while。
比如下面这个例子。
// 直接爆栈了
function runStack(n) {
if (n === 0) return 100;
return runStack(n - 2);
}
runStack(50000); // Uncaught RangeError: Maximum call stack size exceeded
2
3
4
5
6
可以使用 while 解决:
// 正常输出,不会爆栈
function runStack(n) {
while (true) {
if (n === 0) {
return 100;
}
n = n - 2;
}
}
runStack(50000);
2
3
4
5
6
7
8
9
10
也可以使用蹦床函数解决:
// 正常输出,不会爆栈
function runStack(n) {
if (n === 0) return 100;
return runStack.bind(null, n - 2); // 返回自身的一个版本
}
function trampoline(f) {
while (f && f instanceof Function) {
f = f();
}
return f;
}
trampoline(runStack(50000));
2
3
4
5
6
7
8
9
10
11
12
注意
while 循环的风险就是会陷入死循环,主线程会死掉,所以要记得终止它。而爆栈是内存不够用,主线程还在。
# 📘 闭包
function makePowerFn(power) {
function powerFn(base) {
return Math.pow(base, power);
}
return powerFn;
}
var square = makePowerFn(2);
square(3); // 9
2
3
4
5
6
7
8
虽然外层的 makePowerFn 函数执行完毕,栈上的调用帧被释放,但是堆上的作用域并不被释放,因此 power 依旧可以被 powerFn 函数访问,这样就形成了闭包。
# 📘 范畴与容器
我们可以把范畴想像成一个容器,里面包含两样东西,值和值的变形关系(即函数)。
范畴论使用函数,表达范畴之间的关系。
伴随着范畴论的发展,就发展出一整套函数的运算方法。这套方法起初只用于数学运算,后来有人将它在计算机上实现了,就变成了今天的函数式编程。
本质上,函数式编程只是范畴论的运算方法,跟数理逻辑、微积分、行列式是同一类东西,都是数学方法,只是碰巧它能用来写程序。为什么函数式编程要求函数必须是纯的?因为它是一种数学运算,原始目的是求值,不做其他事情,否则就无法满足函数运算法则了。
# 📘 函子 Functor
函数不仅可以用于同一个范畴中值的转换,还可以用于将一个范畴转成另一个范畴。这就涉及到了函子(Functor)。
函子是函数式编程中最重要的数据类型,也是基本的运算单位和功能单位。它首先是一种范畴,也就是说,是一个容器,包含了值和变形关系。比较特殊的是,它的变形关系可以依次作用于每一个值,将当前容器变形成另一个容器。
jQuery 的
$()返回的对象并不是一个原生的 DOM 对象,而是对于原生对象的一种封装,这在某种意义上就是一个“容器“(但它并不是函数式的)。Functor 是遵守一些特定规则的容器类型。
Functor 是一个对于函数调用抽象,我们赋予容器自己去调用函数的能力。把东西装进一个容器,只留出一个接口 map 给容器外的函数,map 一个函数时,我们让容器自己来运行这个函数,这样容器就可以自由的选择何时何地如何操作这个函数,以致于拥有惰性求值、错误处理、异步调用等非常强大的特性。
var Container = function(x) {
this._value = x;
}
// 函数式编程一般约定,函子有一个 of 方法
Container.of = x => new Container(x);
// 一般约定,函子的标志就是容器具有 map 方法。该方法将容器里的每个值,映射到另一个容器。
Container.prototype.map = function(f) {
return Container.of(f(this._value));
}
Container.of(3)
.map(x => x + 1) // Container(4)
.map(x => 'Result is ' + x); // Container('Result is 4')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- ES6 创建一个简单的函子。
class Functor {
constructor(val) {
this.val = val;
}
map(f) {
return new Functor(f(this.val));
}
}
(new Functor(2)).map(function(two) {
return two + 2;
}) // Functor(4)
2
3
4
5
6
7
8
9
10
11
上面的例子说明,函数式编程里面的运算,都是通过函子完成,即运算不直接针对值,而是针对这个值的容器——函子。函子本身具有对外接口(map 方法),各种函数就是运算符,通过接口接入容器,引发容器里面的值的变形。
因此,学习函数式编程,实际上就是学习函子的各种运算。由于可以把运算方法封装在函子里面,所以又衍生出各种不同类型的函子,有多少种运算,就有多少种函子。函数式编程就变成了运用不同的函子,解决实际问题。
# 📘 Pointed 函子
函子只是一个实现了 map 契约的接口。Pointed 函子是一个函子的子集。
生成新的函子时,使用了 new 命令,这是在太不像函数式编程了,因为 new 命令是面向对象编程的标志。函数式编程一般约定,函子有一个 of 方法,用来生成新的容器。
Functor.of = function(val) {
return new Functor(val);
}
Functor.of(2).map(function(two) {
return two + 2;
}) // Functor(4)
2
3
4
5
6
// 数组成为一个 Pointed 函子
Array.of('123');
2
# 📘 Maybe 函子
Maybe 用于处理错误和异常。
函子接收各种函数,处理容器里的值。这里就有一个问题:容器内部的值可能是一个空值(比如:null),而外部函数未必有处理空值的机制,如果传入空值,可能就会出错。
// Maybe 函子
var Maybe = function(x) {
this.__value = x;
}
Maybe.of = function(x) {
return new Maybe(x);
}
Maybe.prototype.map = function(f) {
return this.isNothing() ? Maybe.of(null) : Maybe.of(f(this.__value));
}
Maybe.prototype.isNothing = function() {
return (this.__value === null || this.__value === undefined);
}
2
3
4
5
6
7
8
9
10
11
12
13
Functor.of(null).map(function(s) {
return s.toUpperCase();
})
class Maybe extends Functor {
map(f) {
return this.val ? Maybe.of(f(this.val)) : Maybe.of(null);
}
}
Maybe.of(null).map(function(s) {
return s.toUpperCase();
}) // Maybe(null)
2
3
4
5
6
7
8
9
10
11
12
13
# 📘 Either 函子
我们的容器能做的事情太少了,try/catch/throw 并不是 “纯” 的,因为它从外部接管了我们的函数,并且在这个函数出错时抛弃了它的返回值。
Promise 是可以调用 catch 来集中处理错误的。
事实上 Either 并不只是用来做错误处理的,它表示了逻辑或,范畴学里的 coproduc。
条件运算
if ... else ...是最常见的运算之一,在函数式编程里,使用 Either 函子表达。Either 函子内部有两个值:左值(Left)和右值(Right)。右值是在正常情况下使用的值,左值是右值不存在时使用的默认值。
class Either extends Functor {
constructor(left, right) {
this.left = left;
this.right = right;
}
map(f) {
return this.right ?
Either.of(this.left, f(this.right)) :
Either.of(f(this.left), this.right);
}
}
Either.of = function (left, right) {
return new Either(left, right);
};
var addOne = function (x) {
return x + 1;
};
Either.of(5, 6).map(addOne); // Either(5, 7);
Either.of(1, null).map(addOne); // Either(2, null);
Either.of({address: 'xxx'}, currentUser.address).map(updateField);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
var Left = function(x) {
this._value = x;
}
var Right = function(x) {
this._value = x;
}
Left.of = function(x) {
return new Left(x);
}
Right.of = function(x) {
return new Right(x);
}
// 这里不同!
Left.prototype.map = function(f) {
return this;
}
Right.prototype.map = function(f) {
return Right.of(f(this._value));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- Left 和 Right 唯一的区别就是 map 方法的实现。Right.map 的行为跟我们之前提到的 map 函数一样。但是 Left.map 就很不同了:它不会对容器做任何事情,只是很简单的把这个容器拿进来又扔出去。这个特性意味着,Left 可以用来传递一个错误消息。
var getAge = user => user.age ? Right.of(user.age) : Left.of("ERROR!");
getAge({ name: 'stark', age: '21' }).map(age => 'Age is ' + age); //=> Right('Age is 21')
getAge({ name: 'stark' }).map(age => 'Age is ' + age); //=> Left('ERROR!')
2
3
Left 可以让调用链中任意一环的错误立刻返回到调用链尾部,这给我们错误处理带来了很大的方便,再也不用一层一层的 try/catch。
# 📘 AP 函子
- 函子里面包含的值,完全可能是函数。我们可以想象这样一种情况,一个函子的值是数值,另一个函子的值是函数。
class Ap extends Functor {
ap(F) {
return Ap.of(this.val(F.val));
}
}
Ap.of(addTwo).ap(Functor.of(2));
2
3
4
5
6
7
# 📘 IO
- 真正的函数总是要去接触肮脏的世界。
function readLocalStorage() {
return window.localStorage;
}
2
3
IO 跟前面那几个 Functor 不同的地方在于,它的 _value 是一个函数。它把不纯的操作(比如 IO、网络请求、DOM)包裹到一个函数内,从而延迟这个操作的执行。所以我们认为,IO 包含的是被包裹的操作的返回值。
IO 其实也算是惰性求值。
import _ from 'lodash';
var compose = _.flowRight;
var IO = function(f) {
this.__value = f;
}
IO.of = x => new IO(_ => x);
IO.prototype.map = function(f) {
return new IO(compose(f, this.__value))
};
2
3
4
5
6
7
8
9
import _ from 'lodash';
var compose = _.flowRight;
class IO extends Monad{
map(f){
return IO.of(compose(f, this.__value))
}
}
2
3
4
5
6
7
var fs = require('fs');
var readFile = function(filename) {
return new IO(function() {
return fs.readFileSync(filename, 'utf-8');
});
};
readFile('./user.txt').flatMap(tail).flatMap(print);
// 等同于
readFile('./user.txt').chain(tail).chain(print);
2
3
4
5
6
7
8
9
10
# 📘 Monad
Monad 就是一种设计模式,表示将一个运算过程,通过函数拆解成互相连接的多个步骤。你只要提供下一步运算所需的函数,整个运算就会自动执行下去。
Promise 就是一种 Monad。
Monad 让我们避开了嵌套地狱,可以轻松的进行深度嵌套的函数式编程,比如 IO 和其它异步任务。
记得让上面的 IO 集成 Monad。
Monad 函子的作用是,总是返回一个单层的函子。它有一个 faltMap 方法,与 map 方法作用相同。唯一的区别就是如果生成了一个嵌套函子,它会取出后者内部的值,保证返回的永远是一个单层的容器,不会出现嵌套的情况。
class Monad extends Functor {
join() {
return this.val;
}
flatMap(f) {
return this.map(f).join();
}
}
2
3
4
5
6
7
8
如果函数 f 返回的是一个函子,那么 this.map(f) 就会生成一个嵌套的函子。所以,join 方法保证了 flatMap 方法总是返回一个单层的函子。这意味着嵌套的函子会被铺平(flattern)。
# 📚 函数式编程术语
# 📚 当下函数式编程比较火热的库
RxJS (opens new window):响应式函数式编程库(FRP),可以算是 JavaScript 顶级的库之一了。
Cycle.js (opens new window):用于可预测代码的功能性和反应式 JavaScript 框架。
Lodash (opens new window):一个一致性、模块化、高性能的 JavaScript 实用工具库。
Lazy.js (opens new window):惰性求值、惰性链。
Underscore.js (opens new window):提供了大量有用的函数式编程助手,而无需扩展任何内置对象。
Ramda (opens new window):一款实用的 JavaScript 函数式编程库。
Sanctuary (opens new window):JavaScript 函数式编程库,比 Ramda 更严格,还提供了 Maybe 和 Either 两种数据类型。
Recompose (opens new window):React Hooks 的鼻祖。
redux-observable (opens new window):Redux 的基于 RxJS 的中间件。 编写和取消异步操作以创建副作用等。
fp-ts (opens new window):TypeScript 中的函数式编程。
Immer (opens new window):只需修改当前树即可创建下一个不可变状态树。
monet.js (opens new window):JavaScript 的 Monadic 类型库。
Folktale (opens new window):JavaScript 函数式编程的标准库。
Elm (opens new window):一种编译成 JavaScript 的函数式语言。它可以帮助您制作网站和网络应用程序,是非常强调简单性和高质量的工具。
io-ts (opens new window):用于 IO 解码/编码的运行时类型系统。
scramjet (opens new window):配合 Node.js 转换流式数据的链式函数编程库。
# 📚 函数式编程的实际应用场景
易调试、热部署、并发
单元测试
← 常见的安全问题 《看完就够用的函数式编程》 →