Node.js API
# Node.js API
# Node.js HTTP
NodeJS HTTP (opens new window)
const http = require("http");
const fs = require("fs");
http
.createServer(function(req, res) {
if (req.url == "/favicon.ico") {
res.writeHead(200);
res.end();
return;
}
res.writeHead(200);
fs.createReadStream(__dirname + "/index.html").pipe(res);
})
.listen(3000);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Node.js 非阻塞 I/O

Node.js 线程部分是非阻塞 I/O,C++ 线程部分是阻塞 I/O。
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态。
阻塞就是做不完不准回来。
非阻塞就是你先做,我先看看有其他事没有,做完了告诉我一声。
// 阻塞 I/O
var fs = require("fs");
// 读取文件阻塞时使用 readFileSync 方法,非阻塞使用 readFile() 方法
var data = fs.readFileSync("test.html");
// 加上 toString 才能够正确输出文件里的内容而不是16进制码
console.log(data.toString());
2
3
4
5
6
7
8
// 非阻塞 I/O
var fs = require("fs");
var data = fs.readFile("test.html", function(err, data) {
// 容错处理
if (err) {
return console.error(err);
}
console.log(data.toString());
});
console.log("程序执行完毕!");
2
3
4
5
6
7
8
9
10
11
12
输出结果是先输出 “程序执行完毕!”,再输出文件内容,这就体现了非阻塞代码的特点。
# Node.js 事件驱动机制
Node.js 事件循环 (opens new window)
Node.js EventEmitter (opens new window)
Node.js Events (opens new window)
1. 事件驱动模型
要理解下图的事件驱动模型,首先要先明白 Node.js 的运行机制。
Node.js 本身是单线程、单进程的,需要通过事件或者回调来实现并发效果。因此,Node.js 因为不像多线程那样需要做很多额外的工作,所以性能比较高。
Node.js 中每一个 api 都是异步执行的,并且是各自作为一个独立的线程在运行,使用异步函数调用我们就可以使用这种机制来进行并发处理。Node.js 中几乎所有的事件机制都是依据观察者模式来是实现的。
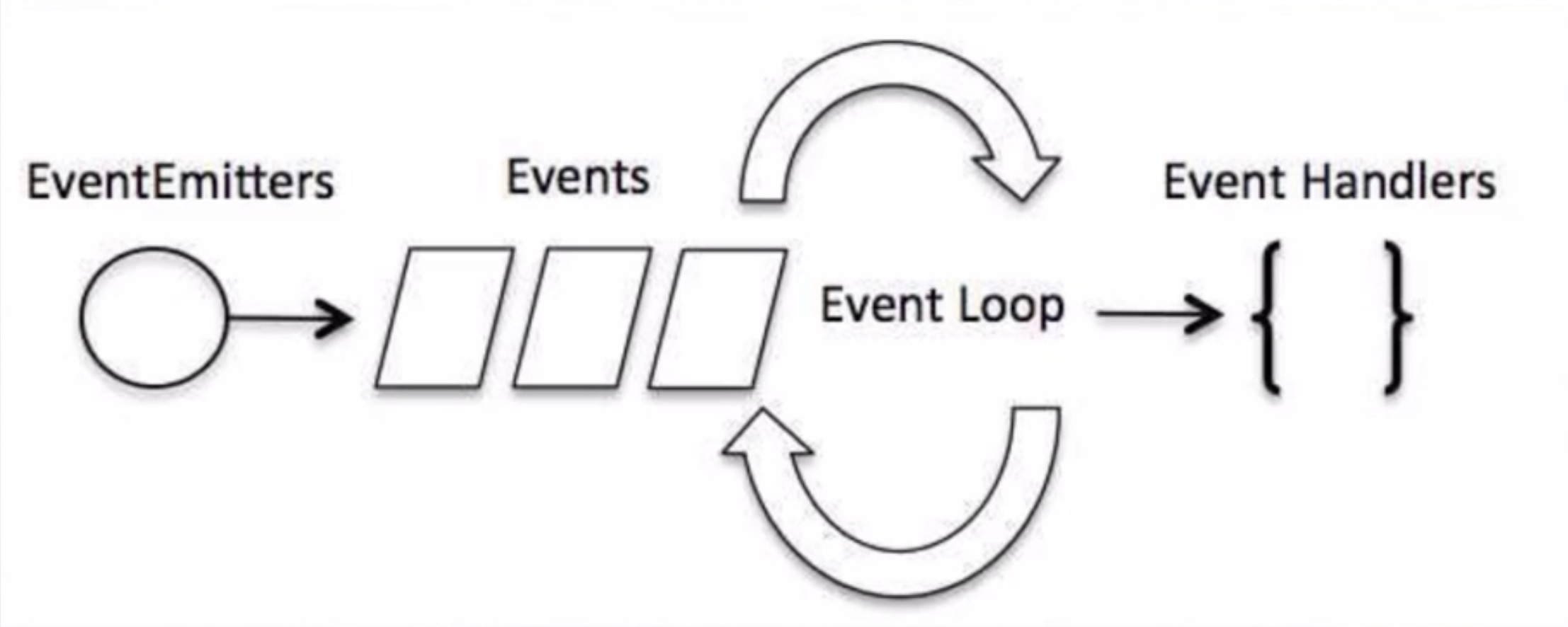
这个模型也叫做非阻塞时 IO 或 事件驱动的 IO 模型。
2. 事件处理代码流程
(1)引入 events 对象,创建 eventEmitter 对象。
(2)绑定事件处理程序。
(3)触发事件。
// 引入 events 模块并创建 eventEmitter 对象
var events = require("events");
var eventEmitter = new events.EventEmitter();
// 绑定事件处理函数
var connectHandler = function connected() {
console.log("connected 被调用!");
};
eventEmitter.on("connection", connectHandler); // 完成事件绑定
// 触发事件
eventEmitter.emit("connection");
console.log("程序执行完毕!");
2
3
4
5
6
7
8
9
10
11
12
13
14
# Node.js 模块化
Node.js 模块系统 (opens new window)
NodeJS CommonJS modules (opens new window)
1. 模块化的概念和意义
为了让 Node.js 的文件可以相互调用,Node.js 提供了一个简单的模块系统。
模块是 Node.js 应用程序的基本组成部分。
文件和模块是一一对应的。一个 Node.js 文件就是一个模块。
这个文件可能是 JavaScript 代码、JSON 或者编译过的 C/C++ 扩展。
Node.js 存在 4 类模块(原生模块和 3 种文件模块)。
2. Node.js 模块加载流程
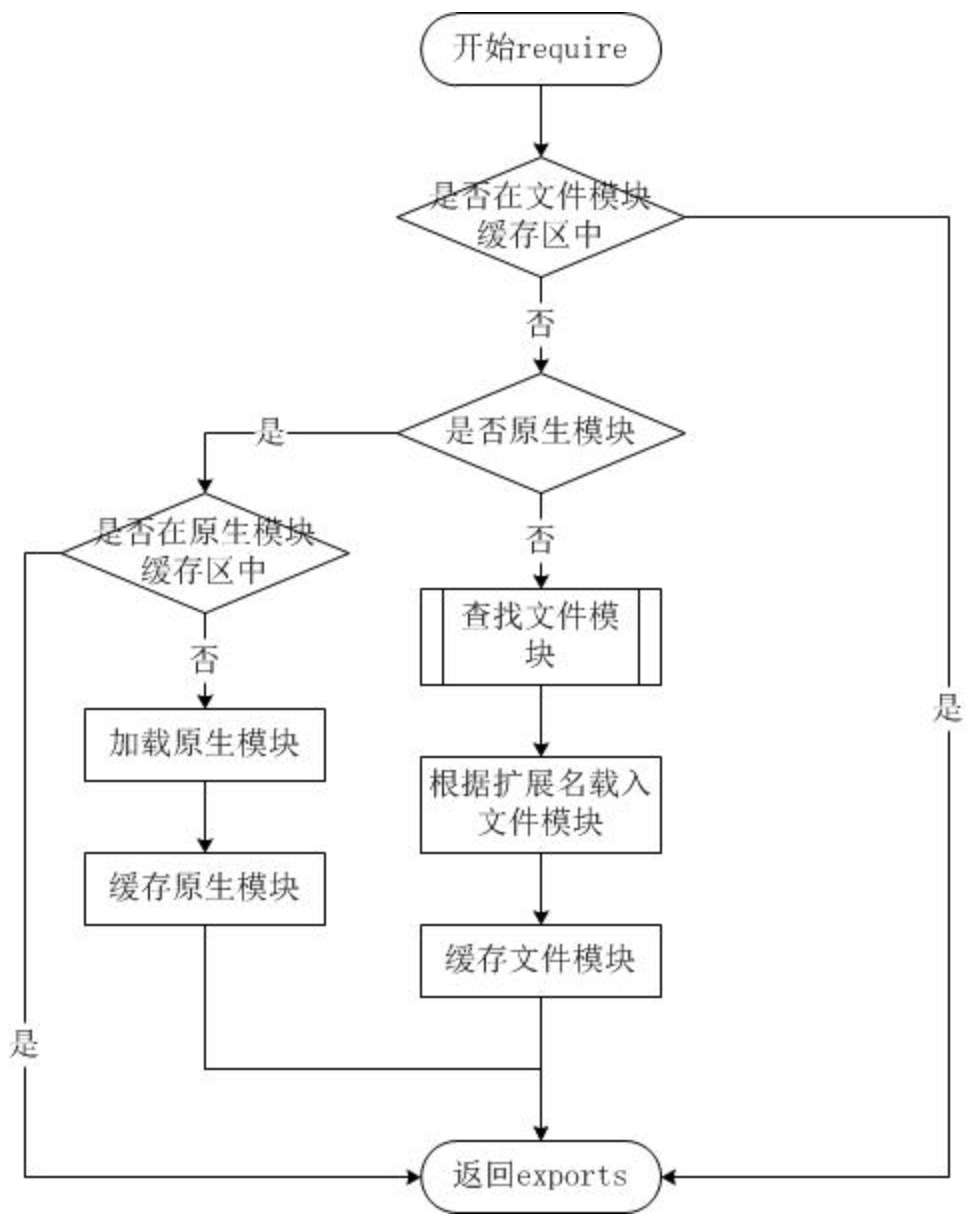
3. Node.js 的模块加载方式
从文件模块缓存区中加载。
从文件中加载。
从原生模块缓存区中加载。
从原生模块中加载。
4. require 方法加载模块
require 方法接受以下几种参数的传递:
http、fs、path 等原生模块。
./mod 或 ../mod,相对路径的文件模块。
/pathtomodule/mod,绝对路径的文件模块。
mod,非原生模块的文件模块。
// test.js
function Hello() {
var name;
this.setName = function(argName) {
name = argName;
};
this.sayHello = function() {
console.log("Hello " + name);
};
}
module.exports = Hello;
2
3
4
5
6
7
8
9
10
11
// main.js
var Hello = require("./test");
hello = new Hello();
hello.setName("Shen Zhen");
hello.sayHello();
2
3
4
5
6
# Node.js 异步编程
# callback
回调函数的格式规范:第一个参数是 error,后面的参数才是结果。
异步流程控制:async.js (opens new window)。
# promise
resolved 状态的 Promise 会回调后面的第一个 .then。
rejected 状态的 Promise 会回调后面的第一个 .catch。
任何一个 rejected 状态且后面没有 .catch 的 Promise,都会造成浏览器或 node 环境的全局错误。
执行 then 和 catch 会返回一个新 Promise,该 Promise 最终状态根据 then 和 catch 的回调函数的执行结果决定。
如果回调函数最终是 throw,该 Promise 是 rejected 状态;
如果回调函数最终是 return,该 Promise 是 resolved 状态;
但如果回调函数最终 return 了一个 Promise ,该 Promise 会和回调函数 return 的 Promise 状态保持一致。
/**
* 进行三轮面试,都通过之后征求所有家庭成员的同意
* 只要有一处不通过则面试失败
*/
interview(1)
.then(() => {
return interview(2);
})
.then(() => {
return interview(3);
})
.then(() => {
return Promise.all([
family("father").catch(() => {
/* 忽略老爸的的反对意见 */
}),
family("mother"),
family("wife")
]).catch((e) => {
e.round = "family";
throw e;
});
})
.then(() => {
console.log("success");
})
.catch((err) => {
console.log("cry at " + err.round);
});
function interview(round) {
return new Promise((resolve, reject) => {
setTimeout(() => {
if (Math.random() < 0.2) {
const error = new Error("failed");
error.round = round;
reject(error);
} else {
resolve("success");
}
}, 500);
});
}
function family(name) {
return new Promise((resolve, reject) => {
setTimeout(() => {
if (Math.random() < 0.2) {
const error = new Error("disagree");
error.name = name;
reject(error);
} else {
resolve("agree");
}
}, Math.random() * 400);
});
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# async/await
async function 是 Promise 的语法糖封装。
异步编程的终极方案 – 以同步的方式写异步。
await 关键字可以 “暂停” async function 的执行;
await 关键字可以以同步的写法获取 Promise 的执行结果;
try-catch 可以获取 await 所得到的错误。
一个穿越事件循环存在的 function。
(async function() {
await findJob();
console.log("trip");
})();
async function findJob() {
try {
// 进行三轮面试
await interview(1);
await interview(2);
await interview(3);
try {
// 征求多个家庭成员的意见
await Promise.all([
family("father").catch(() => {
/* 老爸说的话当耳边风 */
}),
family("mother"),
family("wife")
]);
} catch (e) {
e.round = "family";
throw e;
}
console.log("smile");
} catch (e) {
console.log("cry at " + e.round);
}
}
function interview(round) {
return new Promise((resolve, reject) => {
setTimeout(() => {
if (Math.random() < 0.2) {
const error = new Error("failed");
error.round = round;
reject(error);
} else {
resolve("success");
}
}, 500);
});
}
function family(name) {
return new Promise((resolve, reject) => {
setTimeout(() => {
if (Math.random() < 0.2) {
const error = new Error("disagree");
error.name = name;
reject(error);
} else {
resolve("agree");
}
}, Math.random() * 400);
});
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# Node.js 路由
下面的例子展示了如何根据访问不同的路由来做不同的事情。
// http.js
var http = require("http");
var url = require("url");
function start(route) {
function onRequest(request, response) {
var pathname = url.parse(request.url).pathname;
route(pathname, response);
}
http.createServer(onRequest).listen(8888);
console.log("Server has started.");
}
exports.start = start;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// router.js
function route(pathname, response) {
if (pathname == "/") {
response.writeHead(200, { "Content-Type": "text/plain" });
response.write("Hello World");
response.end();
} else if (pathname == "/index/home") {
response.end("/index/home");
} else {
response.end("404");
}
}
exports.route = route;
2
3
4
5
6
7
8
9
10
11
12
13
14
// app.js
var server = require("./http");
var router = require("./router");
server.start(router.route);
2
3
4
5
路由有 get/post 请求,并且这两种请求返回的结果是不一样的。Node.js GET/POST 请求 (opens new window)
# Node.js 全局方法和工具
Node.js 全局对象 (opens new window)
Node.js 常用工具 (opens new window)
推荐一个很全的 JavaScript 工具库:Underscore.js (opens new window),它提供了 100 多个函数。
# Node.js 文件系统
Node.js 文件系统 (opens new window)
Node.js Buffer(缓冲区) (opens new window)
应用场景:比如要做一个文件上传系统的时候就需要用到 fs。
# 文件基本知识
文件权限位 mode
Linux 文件基本属性 (opens new window)
windows 文件默认可读可写不可执行,0o666
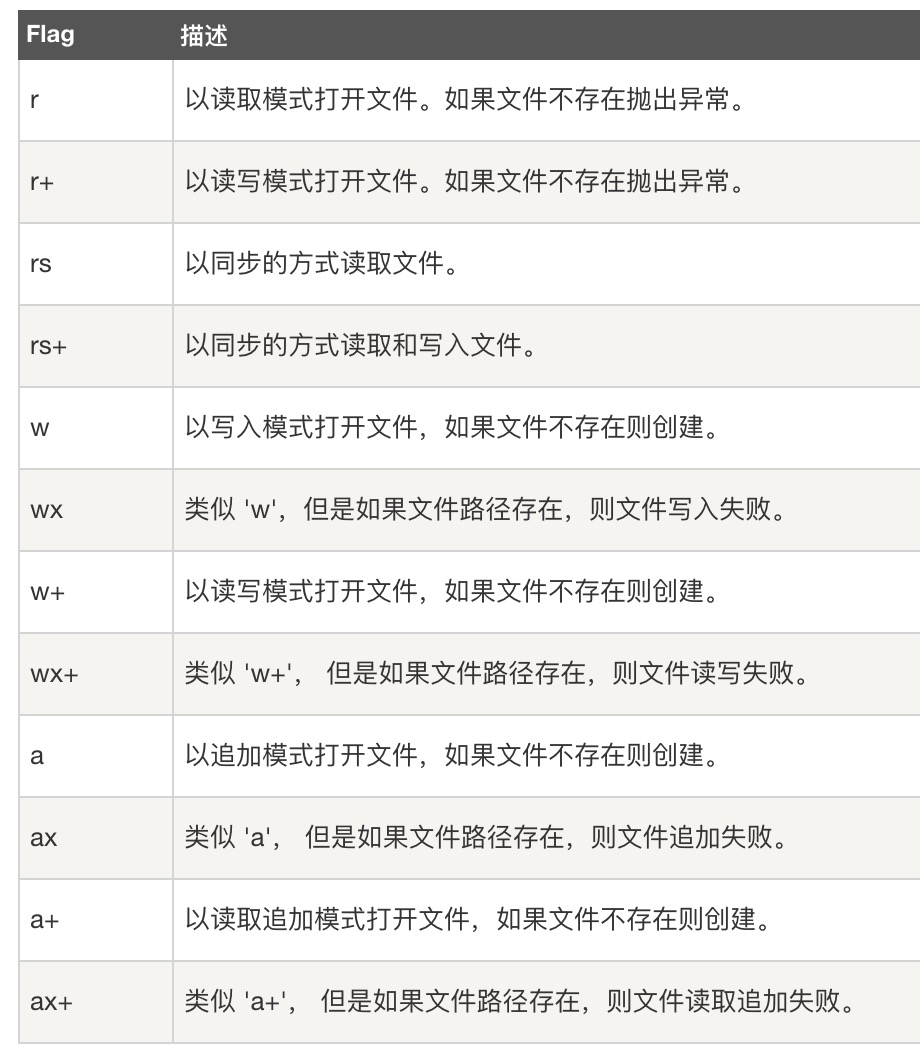
文件标识位 flag
r: 读取
w: 写入
s: 同步
+: 增加相反操作
x: 排它方式
文件描述符 fd
Node.js 中的文件描述符为了抽象不同操作系统间的差异,通过数值的方式来分配,递增的,并且是从 3 开始的,因为 0、1、2 分别被 process.stdin、process.stdout、process.stderr 占用了。
文件描述符是一个文件的唯一标识。
# 文件基本操作
1. 文件读取
const fs = require("fs");
const buf = fs.readFileSync("test.html", { encoding: "utf-8" });
console.log(buf);
2
3
const fs = require("fs");
fs.readFile("test.html", { encoding: "utf-8" }, (err, data) => {
console.log(data);
});
2
3
4
readFile / readFileSync 会一次性将所有文件内容读取到缓存中,如果文件过大,缓存不足时,就可能会出现文件内容丢失的情况。因此,对于大文件,一般不推荐使用这个方法,而是使用 read 方法多次读取到 buffer 中。
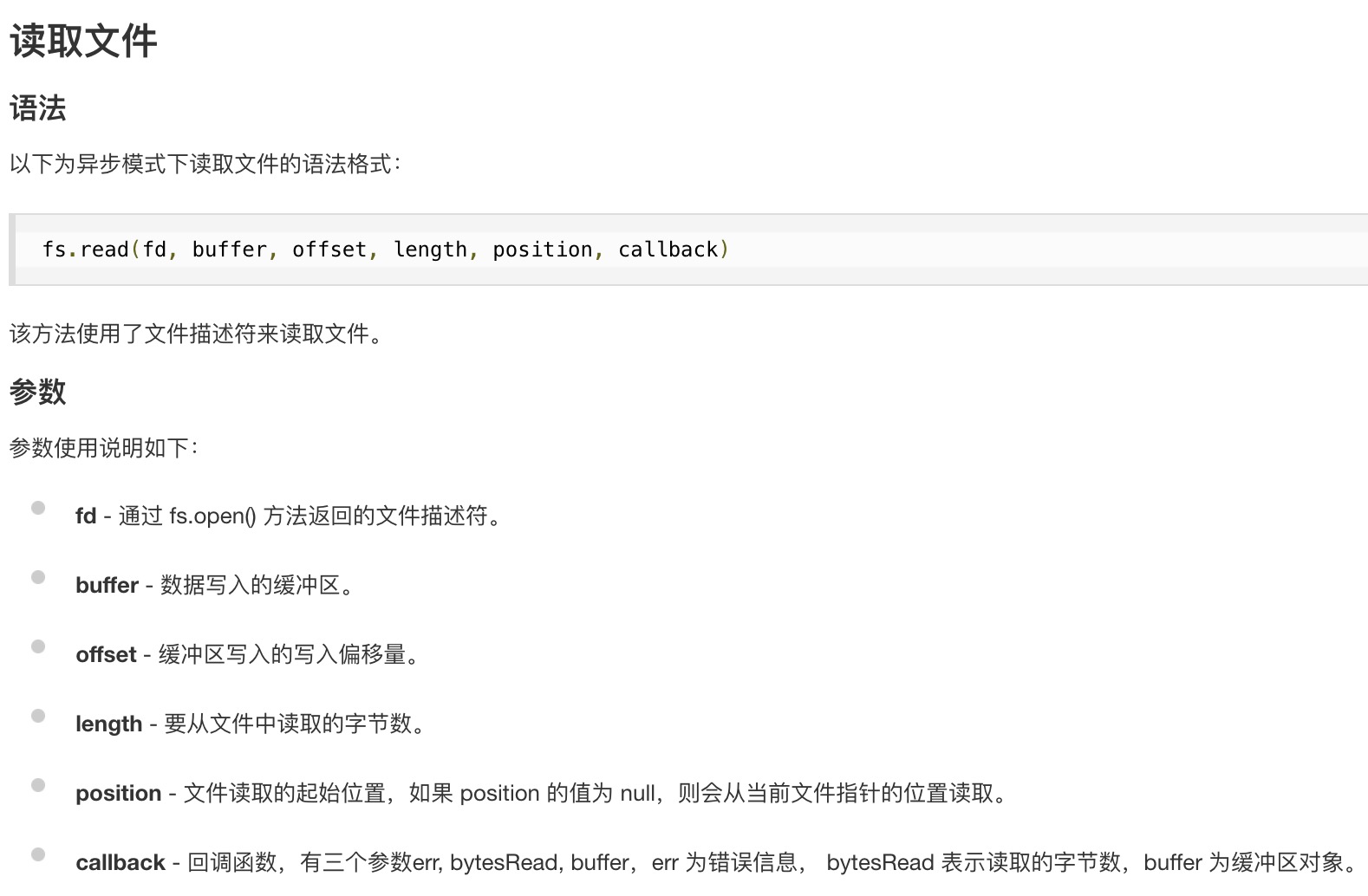
const buf = Buffer.alloc(6);
fs.open("data.txt", "r", (err, fd) => {
// 一个汉字3个字节
fs.read(fd, buf, 0, 3, 0, (err, bytesRead, buffer) => {
console.log(bytesRead); // 实际读取的字节数
console.log(buffer.toString()); // 实际读取的内容
});
});
2
3
4
5
6
7
8
9
2. 文件写入
- 普通写入:后面写入的内容会覆盖掉已有的内容。
const fs = require("fs");
fs.writeFileSync("data.txt", "同步写入");
2
const fs = require("fs");
fs.writeFile("data.txt", "写入的内容", { encoding: "utf-8" }, (err) => {});
2
- 追加写入:后面写入的内容追加到已有内容之后。
const fs = require("fs");
fs.appendFileSync("data.txt", "追加写入");
2
const fs = require("fs");
fs.appendFile("data.txt", "追加写入", (err) => {});
2
- 拷贝写入:拷贝一个文件的内容到另一个文件里。
const fs = require("fs");
fs.copyFileSync("data.txt", "datacopy.txt");
2
const fs = require("fs");
fs.copyFile("data.txt", "datacopy.txt", (err) => {});
2
- 用读写操作模拟拷贝文件
function copy(file, target) {
const data = fs.readFileSync(file);
fs.writeFileSync(target, data);
}
copy("data.txt", "data1.txt");
2
3
4
5
- 多次写入 write

const buf = Buffer.from("深圳大学");
fs.open("data.txt", "r+", (err, fd) => {
fs.write(fd, buf, 0, 6, 3, (err, size, buf) => {
fs.close(fd, (err) => {
console.log("写入成功,关闭文件!");
});
});
});
2
3
4
5
6
7
8
9
3. 打开文件
// 打印的文件描述符是递增的
fs.open("data.txt", "r", (err, fd) => {
console.log(fd);
fs.open("data1.txt", "r", (err, fd) => {
console.log(fd);
});
});
2
3
4
5
6
7
4. 关闭文件
fs.open("data.txt", "r", (err, fd) => {
fs.close(fd, (err) => {
console.log("关闭成功!");
});
});
2
3
4
5
5. 删除文件
fs.unlinkSync("data.txt");
fs.unlink("data.txt", (err) => {});
# 文件目录基本操作
1. 查看目录权限
try {
fs.accessSync("./");
console.log("可读可写");
} catch (e) {
console.log("不可访问");
}
2
3
4
5
6
fs.access("./", (err) => {
if (err) {
console.log("不可访问");
} else {
console.log("可读可写");
}
});
2
3
4
5
6
7
2. 获取文件目录的信息
let file = fs.statSync("dir/dir.txt");
console.log(file);
2
let file = fs.stat("dir/dir.txt", (err, data) => {
console.log(data);
});
2
3
3. 创建目录

创建目录时需要注意的一点就是要保证创建的目录的上一级目录是存在的,比如这里的 dir 目录必须存在,否则会报错。
我们也可以添加 recursive: true 参数,不管创建的目录 dir 是否存在。
fs.mkdirSync("dir/a");
fs.mkdir("dir/a", { recursive: true }, (err) => {});
4. 读取目录
console.log(fs.readdirSync("dir/a")); // []
fs.readdir("dir/a", (err, files) => {});
5. 删除目录
fs.rmdirSync("dir2/a");
fs.rmdir("dir2/a", (err) => {});
# 读取并操作当前目录下的所有文件
配合 promise 和 async/await 读取目录下的所有文件,并进行操作。
const fs = require("fs");
const path = require("path");
function getFile() {
return new Promise((resolve, reject) => {
const filePath = path.resolve(__dirname, "./dir");
fs.readdir(filePath, (err, files) => {
const fileArr = [];
files.forEach((fileName) => {
fileArr.push("/dir/" + fileName);
});
resolve(fileArr);
});
});
}
async function getFilePath() {
const result = await getFile();
return result;
}
function insertDB() {
getFilePath().then((res) => {
// 在这里可以做一些存进数据库的操作
console.log(res);
});
}
insertDB();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# Node.js Buffer
在 Node.js 中,Buffer (opens new window) 是一个用于处理二进制数据的类。它是一个全局对象,可以通过 Buffer 构造函数来创建。Buffer 类提供了一种在 Node.js 中处理数据流、文件系统操作和网络通信时操作二进制数据的方式。
- 创建 Buffer:可以使用 Buffer.from()、Buffer.alloc() 或 Buffer.allocUnsafe() 等方法创建 Buffer 实例。
// 通过字符串创建 Buffer
const buf1 = Buffer.from('Hello, Node.js');
// 创建指定大小的 Buffer
const buf2 = Buffer.alloc(10); // 创建一个包含 10 个字节的 Buffer
2
3
4
5
- 读写操作:Buffer 实例可以通过索引直接读写二进制数据。
// 读取和写入
const value = buf1[0]; // 读取第一个字节的值
buf1[1] = 100; // 修改第二个字节的值
2
3
- 转换:Buffer 可以和字符串之间相互转换。
// Buffer 和字符串的相互转换
const str = buf1.toString('utf-8'); // 将 Buffer 转换为字符串
const newBuf = Buffer.from(str, 'utf-8'); // 将字符串转换为 Buffer
2
3
- 拷贝:可以使用 copy 方法将一个 Buffer 的内容拷贝到另一个 Buffer 中。
// 拷贝 Buffer
const buf3 = Buffer.alloc(5);
buf1.copy(buf3); // 将 buf1 的内容拷贝到 buf3 中
2
3
- 切片:可以使用 slice 方法创建一个现有 Buffer 的切片。
// 切片 Buffer
const slicedBuf = buf1.slice(0, 5); // 从第 0 个字节到第 4 个字节的切片
2
- 长度和大小:Buffer 的长度是固定的,无法动态调整。可以通过 length 属性获取 Buffer 的长度。
// 获取 Buffer 的长度
const length = buf1.length;
2
- Buffer 与 TypedArray:Buffer 可以与 TypedArray 进行互操作,如 Uint8Array 等。
// Buffer 与 TypedArray 的互操作
const uint8Array = new Uint8Array(buf1);
2
# Node.js 中如何实现多线程
在 Node.js 中,主线程是单线程的,但可以通过一些机制实现多线程的效果。在 Node.js 中实现多线程通常是为了解决一些计算密集型任务,并不是为了并行执行 I/O 操作,因为 Node.js 的事件驱动模型本身已经非常适合处理高并发的 I/O 任务。
# Child Processes(子进程)
Node.js 提供了 child_process (opens new window) 模块,可以创建子进程,并通过进程间的通信来实现多线程的效果。每个子进程是独立运行的,有自己的事件循环。
const { fork } = require('child_process');
// 创建子进程
const child = fork('child.js');
// 通过事件进行通信
child.on('message', (message) => {
console.log('Message from child:', message);
});
// 向子进程发送消息
child.send({ hello: 'world' });
2
3
4
5
6
7
8
9
10
11
12
# Worker Threads(工作线程)
Node.js 也提供了 worker_threads (opens new window) 模块,这个模块允许在单个进程中创建多个线程。Worker Threads 直接共享内存,但通过 postMessage 和 onmessage 进行通信。
Worker Threads 适用于处理计算密集型任务,因为它们可以在多个 CPU 核心上并行运行。
const { Worker } = require('worker_threads');
// 创建工作线程
const worker = new Worker('worker.js');
// 向工作线程发送消息
worker.postMessage({ hello: 'world' });
// 在工作线程中监听消息
worker.on('message', (message) => {
console.log('Message from worker:', message);
});
2
3
4
5
6
7
8
9
10
11
12
# Cluster 模块
cluster (opens new window) 模块允许在一个主进程中创建多个工作进程,每个工作进程运行在独立的线程中。
const cluster = require('cluster');
const os = require('os');
if (cluster.isMaster) {
// 在主进程中创建多个工作进程
for (let i = 0; i < os.cpus().length; i++) {
cluster.fork();
}
} else {
// 在工作进程中执行具体的任务
console.log('Worker process');
}
2
3
4
5
6
7
8
9
10
11
12
# Node.js Stream(流)
Node.js Stream(流) (opens new window)
1. 为什么要使用流?
流是逐块(chunk)读取数据的,适合读取大数据量的大文件。因此,能够提高内存效率和时间效率。
const fs = require("fs");
// 创建可读流
const rs = fs.createReadStream("demo.mp4");
// 创建可写流
const ws = fs.createWriteStream("copt.mp4");
rs.on("data", (chunk) => {
ws.write(chunk);
});
rs.on("end", () => {
ws.end();
});
2
3
4
5
6
7
8
9
10
11
12
13
但是上面这段代码可能会有问题,因为可读流和可写流的速度可能不一致,比如现在已经读取了 200M 的数据,目前只写入了 100M 的数据,但是读取还是在进行,就可能会导致数据丢失。正常的操作应该是读取一段写完后,再读取下一段。所以,为了保持读写速度一致,需要用到管道流 pipe。
const fs = require("fs");
// 创建可读流
const rs = fs.createReadStream("demo.mp4");
// 创建可写流
const ws = fs.createWriteStream("copt.mp4");
// pipe 只是可读流的方法,所以不能这么用 ws.pipe(rs);
rs.pipe(ws);
2
3
4
5
6
7
8
2. 流的类型
可读流 Readable
可写流 Writable
双工流 Duplex
转换流 Transform
所有的 Stream 对象都是 EventEmitter 的实例。常用的事件如下:
data - 当有数据可读时触发。
end - 没有更多的数据可读时触发。
error - 在接收和写入过程中发生错误时触发。
finish - 所有数据已被写入到底层系统时触发。
3. 例子演示
(1)流的缓冲区默认是16k(1k(KB) 等于 1024 字节(B)),这个大小可以通过 highWaterMark 来改。
const fs = require("fs");
// 创建可读流
const rs = fs.createReadStream("data.txt", {
encoding: "utf-8", // 设置编码格式
highWaterMark: 6 // 设置缓冲区大小,单位是字节 bytes
});
rs.on("data", (chunk) => {
console.log(chunk);
});
rs.on("end", () => {
console.log("读取完毕!");
});
2
3
4
5
6
7
8
9
10
11
12
13
14
执行结果如下:
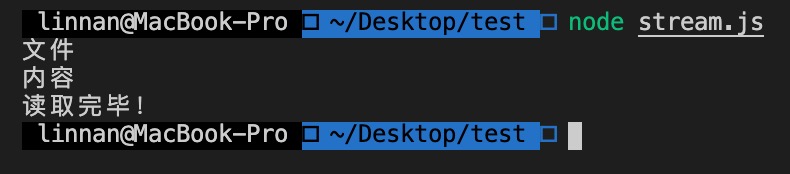
可以看到,读取了两次,每次读取两个汉字,共 6 个字节。
(2)监听常见的事件。
const fs = require("fs");
// 创建可读流
const rs = fs.createReadStream("data.txt", {
encoding: "utf-8",
highWaterMark: 6 // 设置缓冲区大小,单位是字节 bytes
});
rs.on("open", () => {
console.log("打开文件");
});
rs.on("data", (chunk) => {
console.log(chunk);
});
rs.on("end", () => {
console.log("读取完毕!");
});
rs.on("error", () => {
console.log("读取出错!");
});
rs.on("close", () => {
console.log("关闭文件");
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
(3)可读流有两种模式:自动流动(flowing 模式)手动流动(paused 模式)。
// 自动流动模式
// 触发自动流动模式的方法有:监听 data 事件、rs.resume()、rs.pipe()
rs.on("data", (chunk) => {
console.log(chunk);
});
2
3
4
5
// 手动流动模式
// 触发手动流动模式的方法有:监听 readable 事件,并且每次都需要手动调用 read 方法读取;rs.pause()
let data = "";
rs.on("readable", () => {
while ((chunk = rs.read()) !== null) {
data += chunk;
}
});
2
3
4
5
6
7
8
(4)可读流完成监听 end 事件;可写流完成监听 finish 事件,并且用 ws.end() 来标记文件末尾。
(5)设置编码格式时,除了都可以在创建流的时候设置之外,可读流还可以使用 rs.setEncoding('utf-8') 设置,可写流可以在写入的时候 ws.write(data, 'utf-8')设置。
(6)双工流就同时具有可读流和可写流的方法,常见的比如用来实现聊天系统 socket。
(7)转换流继承自双工流。需要注意的是,转换流需要自己实现一个 transform 方法。
const stream = require("stream");
const transform = stream.Transform({
// 需要自己实现一个 transform 方法
transform(chunk, encoding, cb) {
// 大小写字母转换,并 push 到缓冲区
this.push(chunk.toString().toLowerCase());
// cb();
}
});
transform.write("D");
console.log("转换成小写字母:" + transform.read().toString());
2
3
4
5
6
7
8
9
10
11
(8)链式流,一般用于管道操作。
使用链式流来压缩文件。
const fs = require("fs");
const zlib = require("zlib");
fs.createReadStream("data.txt")
.pipe(zlib.createGzip())
.pipe(fs.createWriteStream("data.txt.gz"));
console.log("压缩完成!");
2
3
4
5
6
7
8
🔔 逐行读取的最佳方案 readline。下面这个例子展示了逐行读取日志文件并统计访问某个网站的次数。
const fs = require("fs");
const path = require("path");
const readLine = require("readline");
const filename = path.resolve(__dirname, "log.txt");
const readStream = fs.createReadStream(filename);
let num = 0;
// 创建 readline 对象
const readL = readLine.createInterface({
// 输入
input: readStream
});
readL.on("line", (data) => {
if (data.indexOf("https://www.baidu.com") !== -1) {
num++;
}
console.log(data);
});
readL.on("close", () => {
console.log("读取完成!", num);
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// log.txt
访问时间:2020.06.25 17:44:30,访问地址:https://www.baidu.com
访问时间:2020.06.25 17:44:33,访问地址:https://www.baidu.com
访问时间:2020.06.25 17:44:35,访问地址:https://www.baidu123.com
访问时间:2020.06.25 17:44:40,访问地址:https://www.baidu.com
2
3
4
5
执行结果如下:

(9)为什么流要设计成默认是二进制格式的呢?
主要是为了优化 IO 操作,因为不同文件的数据格式是未知的,有可能是字符串、音频、网络包等,而二进制是通用的格式,哪个系统都认识,并且使用二进制进行数据流动和传输也是效率最高的,所以直接使用二进制是最明智的选择。
其实不仅仅是流采用二进制的格式,其他地方的文件传输操作用的也是这种方式。
# Node.js Net
Node.js Net 模块 (opens new window)
1. 常用的跟信息交互通信相关的模块是 net 和 http。net 模块是基于 TCP 封装的,这也是 nodejs 的核心模块之一。http 模块本质上还是 TCP 层的,只不过做了比较多的数据封装。
2. net 模块的组成
net.server,内部是通过 socket 来实现与客户端的通信的。
net.socket,相当于是本地 socket 的 node 版实现,实现了全双工的 stream 接口。
3. 服务端和客户端的通信
首先要在服务端和客户端之间建立一条管道,这条管道是双向的。
server(服务端) pipe client(客户端)
管道如何建立呢?首先服务端要监听一个端口 port,比如:8080,然后客户端访问这个端口,两者就可以进行数据通信了。
4. 服务端和客户端交互的例子
服务端代码
/**
* 服务端创建需要3步
* 1、创建服务 createServer
* 2、监听端口 listen,等待客户端接入
* 3、socket 通信,监听 data、close 等事件完成与客户端交互
*/
const net = require("net");
// 创建 tcp 服务
const server = net.createServer();
// 监听8000端口
server.listen("8000");
server.on("listening", function() {
console.log("监听成功,监听端口号是8000!");
});
// 监听新建立的连接
server.on("connection", (socket) => {
console.log("新的连接建立成功!");
// 监听客户端传过来的信息
socket.on("data", (data) => {
console.log("服务端收到客户端传过来的信息是:", data.toString());
// 返回给客户端一些数据
socket.write("你好,我是服务端!");
socket.write("客户端请关闭连接");
});
// 关闭连接
server.close();
});
// 监听连接是否正常关闭
server.on("close", () => {
console.log("服务端已经断开连接!");
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
客户端代码
/**
* 客户端创建也需要3步
* 1、创建 socket
* 2、连接指定的 IP 端口
* 3、监听 data、close 等事件完成与服务端交互
*/
const net = require("net");
// 连接到服务端
// 默认是 localhost,但是也可以设置 IP 地址
const netSocket = net.connect("8000");
netSocket.on("error", () => {
console.log("连接失败!");
});
netSocket.on("connect", () => {
console.log("客户端与服务端的连接已经建立成功!");
netSocket.write("你好,我是客户端!");
// 接收服务端数据
netSocket.on("data", (data) => {
console.log("客户端收到服务端的数据是:", data.toString());
netSocket.end();
});
});
netSocket.on("end", () => {
console.log("客户端关闭连接成功!");
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
执行结果如下:
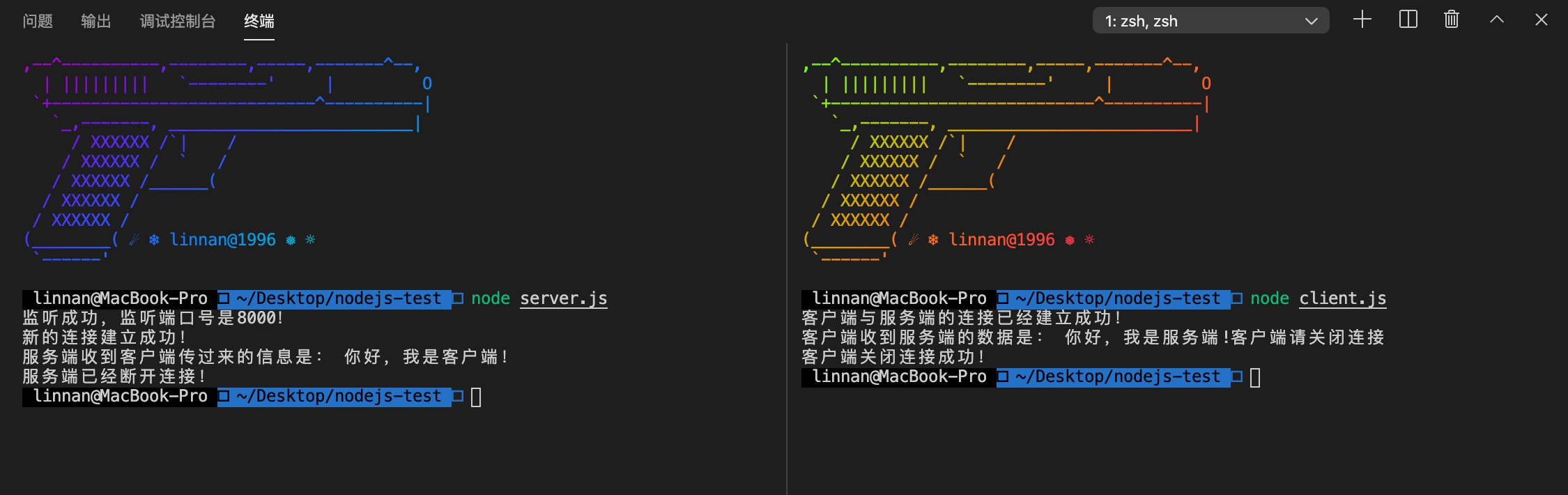
# Node.js RPC 调用
Remote Procedure Call(远程过程调用)
# RPC vs Ajax
RPC 跟 Ajax 相同的地方:
都是两个计算机之间的网络通信;
需要双方约定一个数据格式。
RPC 不同于 Ajax 的地方:
RPC 不一定使用 DNS 作为寻址服务,使用特有服务进行寻址;
应用层协议一般不使用 HTTP,而是使用二进制协议,可以获得更小的数据包体积和更快的编码速率;
基于 TCP 或 UDP 协议,TCP 通信的三种方式:单工通信、半双工通信、全双工通信。
# Buffer 编解码二进制数据包
NodeJS Buffer (opens new window)
Protocol Buffer (opens new window) 是由 Google 研发的二进制协议编解码库,它通过协议文件控制 Buffer 的格式,更直观、更好维护、更便于合作。
protobufjs (opens new window) 是一个纯 JS 实现的 Protocol Buffer 库,带有对 node.js 和浏览器的 TypeScript 支持。
protocol-buffers (opens new window) 是一个专门为 Node.js 设计的 Protocol Buffer 库,能够帮助我们快速编解码二进制数据包。
const fs = require("fs");
const protobuf = require("protocol-buffers");
// 根据协议,编译出一个 js 逻辑对象,里面包含 encode 和 decode 函数
// 实际写 web 服务器的时候,注意这个操作可以直接在进程启动就做
// 否则在 http 处理过程里做的话,是一次不必要的性能消耗
const schemas = protobuf(fs.readFileSync(`${__dirname}/test.proto`));
const buffer = schemas.Course.encode({
id: 4,
name: "aa",
lesson: []
});
console.log(buffer);
console.log(schemas.Course.decode(buffer));
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// test.proto
message Course {
required float id = 1;
required string name = 2;
repeated Lesson lesson = 3;
}
message Lesson {
required float id = 1;
required string title = 2;
}
2
3
4
5
6
7
8
9
10
11
# 使用 Net 搭建多路复用的 RPC 通道
# 1. 单工通信
// client
const net = require("net");
const socket = new net.Socket({});
socket.connect({
host: "127.0.0.1",
port: 4000
});
socket.write("hello");
2
3
4
5
6
7
8
9
10
11
// server
const net = require("net");
const server = net.createServer((socket) => {
socket.on("data", function(buffer) {
console.log(buffer, buffer.toString());
});
});
server.listen(4000);
2
3
4
5
6
7
8
9
10
# 2. 半双工通信
// client
const net = require("net");
// 创建 socket
const socket = new net.Socket({});
// 连接服务器
socket.connect({
host: "127.0.0.1",
port: 4000
});
const lessonids = [
"136797",
"136798",
"136799",
"136800",
"136801",
"136803",
"136804",
"136806",
"136807",
"136808",
"136809",
"141994",
"143517",
"143557",
"143564",
"143644",
"146470",
"146569",
"146582"
];
let id = Math.floor(Math.random() * lessonids.length);
// 往服务器传数据
socket.write(encode(id));
socket.on("data", (buffer) => {
console.log(buffer.toString());
// 接收到数据之后,按照半双工通信的逻辑,马上开始下一次请求
id = Math.floor(Math.random() * lessonids.length);
socket.write(encode(id));
});
// 把编码请求包的逻辑封装为一个函数
function encode(index) {
buffer = Buffer.alloc(4);
buffer.writeInt32BE(lessonids[index]);
return buffer;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
// server
const net = require("net");
// 创建 tcp 服务器
const server = net.createServer((socket) => {
socket.on("data", function(buffer) {
// 从传来的 buffer 里读出一个 int32
const lessonid = buffer.readInt32BE();
// 50 毫秒后回写数据
setTimeout(() => {
socket.write(Buffer.from(data[lessonid]));
}, 50);
});
});
// 监听端口启动服务
server.listen(4000);
const data = {
136797: "01 | 标题",
136798: "02 | 标题",
136799: "03 | 标题",
136800: "04 | 标题",
136801: "05 | 标题",
136803: "06 | 标题",
136804: "07 | 标题",
136806: "08 | 标题",
136807: "09 | 标题",
136808: "10 | 标题",
136809: "11 | 标题",
141994: "12 | 标题",
143517: "13 | 标题",
143557: "14 | 标题",
143564: "15 | 标题",
143644: "16 | 标题",
146470: "17 | 标题",
146569: "18 | 标题",
146582: "19 | 标题"
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# 3. 全双工通信
关键在于应用层协议需要有标记包号的字段
处理以下情况,需要有标记包长的字段
粘包
不完整包
// client
const net = require("net");
const socket = new net.Socket({});
socket.connect({
host: "127.0.0.1",
port: 4000
});
const LESSON_IDS = [
"136797",
"136798",
"136799",
"136800",
"136801",
"136803",
"136804",
"136806",
"136807",
"136808",
"136809",
"141994",
"143517",
"143557",
"143564",
"143644",
"146470",
"146569",
"146582"
];
let id = Math.floor(Math.random() * LESSON_IDS.length);
let oldBuffer = null;
socket.on("data", (buffer) => {
// 把上一次 data 事件使用残余的 buffer 接上来
if (oldBuffer) {
buffer = Buffer.concat([oldBuffer, buffer]);
}
let completeLength = 0;
// 只要还存在可以解成完整包的包长
while ((completeLength = checkComplete(buffer))) {
const package = buffer.slice(0, completeLength);
buffer = buffer.slice(completeLength);
// 把这个包解成数据和 seq
const result = decode(package);
console.log(`包${result.seq},返回值是${result.data}`);
}
// 把残余的 buffer 记下来
oldBuffer = buffer;
});
let seq = 0;
/**
* 二进制包编码函数
* 在一段 rpc 调用里,客户端需要经常编码 rpc 调用时,业务数据的请求包
*/
function encode(data) {
// 正常情况下,这里应该是使用 protobuf 来 encode 一段代表业务数据的数据包
// 为了不要混淆重点,这个例子比较简单,就直接把课程 id 转 buffer 发送
const body = Buffer.alloc(4);
body.writeInt32BE(LESSON_IDS[data.id]);
// 一般来说,一个 rpc 调用的数据包会分为定长的包头和不定长的包体两部分
// 包头的作用就是用来记载包的序号和包的长度,以实现全双工通信
const header = Buffer.alloc(6);
header.writeInt16BE(seq);
header.writeInt32BE(body.length, 2);
// 包头和包体拼起来发送
const buffer = Buffer.concat([header, body]);
console.log(`包${seq}传输的课程id为${LESSON_IDS[data.id]}`);
seq++;
return buffer;
}
/**
* 二进制包解码函数
* 在一段 rpc 调用里,客户端需要经常解码 rpc 调用时,业务数据的返回包
*/
function decode(buffer) {
const header = buffer.slice(0, 6);
const seq = header.readInt16BE();
const body = buffer.slice(6);
return {
seq,
data: body.toString()
};
}
/**
* 检查一段 buffer 是不是一个完整的数据包。
* 具体逻辑是:判断 header 的 bodyLength 字段,看看这段 buffer 是不是长于 header 和 body 的总长
* 如果是,则返回这个包长,意味着这个请求包是完整的。
* 如果不是,则返回 0,意味着包还没接收完
* @param {} buffer
*/
function checkComplete(buffer) {
if (buffer.length < 6) {
return 0;
}
const bodyLength = buffer.readInt32BE(2);
return 6 + bodyLength;
}
for (let k = 0; k < 100; k++) {
id = Math.floor(Math.random() * LESSON_IDS.length);
socket.write(encode({ id }));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
// server
const net = require("net");
const server = net.createServer((socket) => {
let oldBuffer = null;
socket.on("data", function(buffer) {
// 把上一次 data 事件使用残余的 buffer 接上来
if (oldBuffer) {
buffer = Buffer.concat([oldBuffer, buffer]);
}
let packageLength = 0;
// 只要还存在可以解成完整包的包长
while ((packageLength = checkComplete(buffer))) {
const package = buffer.slice(0, packageLength);
buffer = buffer.slice(packageLength);
// 把这个包解成数据和 seq
const result = decode(package);
// 计算得到要返回的结果,并 write 返回
socket.write(encode(LESSON_DATA[result.data], result.seq));
}
// 把残余的 buffer 记下来
oldBuffer = buffer;
});
});
server.listen(4000);
/**
* 二进制包编码函数
* 在一段 rpc 调用里,服务端需要经常编码 rpc 调用时,业务数据的返回包
*/
function encode(data, seq) {
// 正常情况下,这里应该是使用 protobuf 来 encode 一段代表业务数据的数据包
// 为了不要混淆重点,这个例子比较简单,就直接把课程标题转 buffer 返回
const body = Buffer.from(data);
// 一般来说,一个 rpc 调用的数据包会分为定长的包头和不定长的包体两部分
// 包头的作用就是用来记载包的序号和包的长度,以实现全双工通信
const header = Buffer.alloc(6);
header.writeInt16BE(seq);
header.writeInt32BE(body.length, 2);
const buffer = Buffer.concat([header, body]);
return buffer;
}
/**
* 二进制包解码函数
* 在一段rpc调用里,服务端需要经常解码 rpc 调用时,业务数据的请求包
*/
function decode(buffer) {
const header = buffer.slice(0, 6);
const seq = header.readInt16BE();
// 正常情况下,这里应该是使用 protobuf 来 decode 一段代表业务数据的数据包
// 为了不要混淆重点,这个例子比较简单,就直接读一个 Int32 即可
const body = buffer.slice(6).readInt32BE();
// 这里把 seq 和数据返回出去
return {
seq,
data: body
};
}
/**
* 检查一段 buffer 是不是一个完整的数据包
* 具体逻辑是:判断 header 的 bodyLength 字段,看看这段 buffer 是不是长于 header 和 body 的总长
* 如果是,则返回这个包长,意味着这个请求包是完整的。
* 如果不是,则返回 0,意味着包还没接收完
* @param {} buffer
*/
function checkComplete(buffer) {
if (buffer.length < 6) {
return 0;
}
const bodyLength = buffer.readInt32BE(2);
return 6 + bodyLength;
}
// 假数据
const LESSON_DATA = {
136797: "01 | 标题",
136798: "02 | 标题",
136799: "03 | 标题",
136800: "04 | 标题",
136801: "05 | 标题",
136803: "06 | 标题",
136804: "07 | 标题",
136806: "08 | 标题",
136807: "09 | 标题",
136808: "10 | 标题",
136809: "11 | 标题",
141994: "12 | 标题",
143517: "13 | 标题",
143557: "14 | 标题",
143564: "15 | 标题",
143644: "16 | 标题",
146470: "17 | 标题",
146569: "18 | 标题",
146582: "19 | 标题"
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
# Node.js API 服务
# Restful
简单易懂
可以快速搭建
在数据聚合方面有很大劣势
# GraphQL
GraphQL (opens new window) 是一个由 Facebook 提出的应用层查询语言,可以基于图模式定义后端,然后客户端就可以请求所需要的数据集。
Facebook 开发的实现 API 服务的库
专注数据聚合,前端想要什么就返回什么,让前端有 “自定义查询” 数据的能力
下面就是一个使用 GraphQL 实现 api 的例子,运行之后在浏览器中访问 http://localhost:3000/api?query={comment{name,id,praiseNum,...}} 就可以根据自己的需要取出指定的字段来展示。
// server.js
const fs = require("fs");
const app = new (require("koa"))();
const mount = require("koa-mount");
const static = require("koa-static");
const graphqlHTTP = require("koa-graphql");
app.use(
// 给 koa-graphql 传一个 graphql 的协议文件,就会自动帮你生成 graphql-api
mount(
"/api",
graphqlHTTP({
schema: require("./schema")
})
)
);
app.use(mount("/static", static(`${__dirname}/source/static`)));
app.use(
mount("/", async (ctx) => {
ctx.status = 200;
ctx.body = fs.readFileSync(`${__dirname}/source/index.htm`, "utf-8");
})
);
// module.exports = app;
app.listen(3000);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
// schema.js
const { graphql, buildSchema } = require("graphql");
const mockDatabase = require("./mock-database");
const schema = buildSchema(`
type Comment {
id: Int
avatar: String
name: String
isTop: Boolean
content: String
publishDate: String
commentNum: Int
praiseNum: Int
}
type Query {
comment: [Comment]
}
type Mutation {
praise(id: Int): Int
}
`);
schema.getQueryType().getFields().comment.resolve = () => {
return Object.keys(mockDatabase).map((key) => {
return mockDatabase[key];
});
};
schema.getMutationType().getFields().praise.resolve = (args0, { id }) => {
mockDatabase[id].praiseNum++;
return mockDatabase[id].praiseNum;
};
module.exports = schema;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
// mock-database.js
module.exports = {
1: {
id: 1,
avatar:
"https://static001.geekbang.org/account/avatar/00/0f/52/62/1b3ebed5.jpg",
name: "标题一",
isTop: true,
content: "哈哈哈哈",
publishDate: "今天",
commentNum: 10,
praiseNum: 5
},
2: {
id: 2,
avatar:
"https://static001.geekbang.org/account/avatar/00/0f/52/62/1b3ebed5.jpg",
name: "标题二",
isTop: true,
content: "很长的内容",
publishDate: "上周",
commentNum: 10,
praiseNum: 2
},
3: {
id: 3,
avatar:
"https://static001.geekbang.org/account/avatar/00/0f/52/62/1b3ebed5.jpg",
name: "标题三",
isTop: true,
content: "这里的内容更长",
publishDate: "十年前",
commentNum: 10,
praiseNum: 0
}
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# REPL 环境
Node.js 的 REPL 环境就是指当我们在终端输入 node 命令回车之后进入的环境。
在这个环境中可以正常编写代码。退出这个环境有三种方式:按两次 ctrl + c 或者执行 .exit 命令或者按 ctrl + d。
