正则表达式就是一种描述文本内容组成规律的表示方式,常常用来简化文本处理的逻辑。正则常见的三种功能分别是:
校验数据的有效性
查找符合要求的文本
对文本进行切割和替换等操作
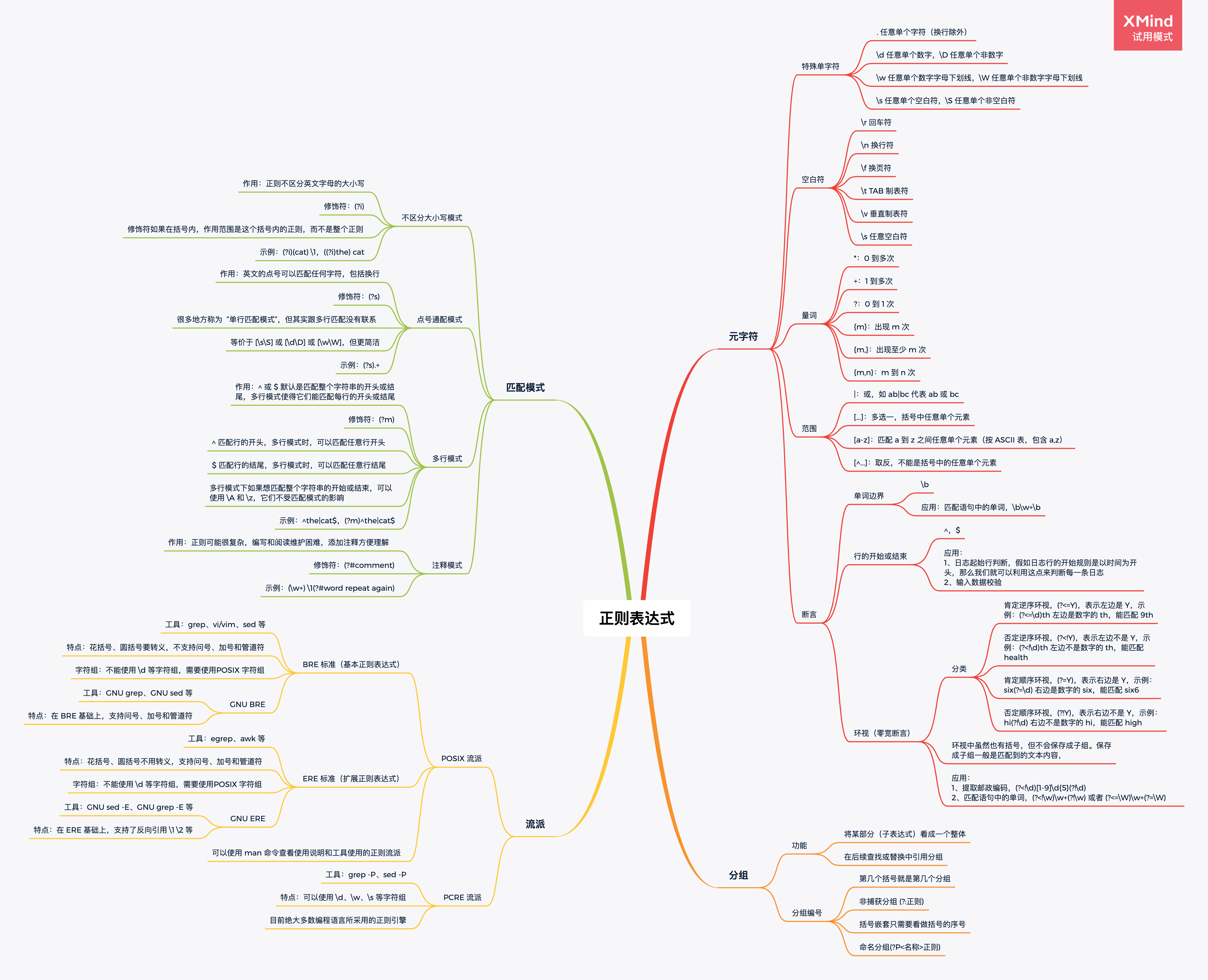
# 元字符
元字符就是指那些在正则表达式中具有特殊意义的专用字符,元字符是构成正则表达式的基本元件。
# 贪婪模式
在正则中,表示次数的量词默认是贪婪的,在贪婪模式下,会尝试尽可能最大长度去匹配。
回溯:后面匹配不上,会吐出已匹配的再尝试。
# 非贪婪模式
非贪婪模式就是在量词后面加上?,会找出长度最小且满足要求的。
回溯:后面匹配不上,会匹配更长再接着尝试。
# 独占模式
贪婪模式和非贪婪模式都需要发生回溯才能完成相应的功能。
独占模式就是在量词后面加上+,类似贪婪匹配,但匹配过程不会发生回溯,匹配不上即失败,因此在一些场合下性能会更好。
注意
并不是所有的语言都支持独占模式,比如 JavaScript、Python、Go 都不支持。
# 分组和编号
# 保存子组
括号在正则中可以用于分组,被括号括起来的部分 “子表达式” 会被保存成一个子组。
第几个括号就是第几个分组。
# 不保存子组
在括号里面的会被保存成子组,但有些情况下,我们可能只想用括号将某些部分看成一个整体,后续不用再用它,类似这种情况,在实际使用时,是没必要保存子组的。不保存子组的格式为:(?:正则)。
不保存子组不但可以提高正则的性能,而且由于子组变少了,在子组计数时也更不容易出错。
\d{15}(\d{3})? // 保存子组
\d{15}(?:\d{3})? // 不保存子组
2
# 命名分组
由于编号得数在第几个位置,后续如果发现正则有问题,改动了括号的个数,还可能导致编号发生变化,因此一些编程语言提供了命名分组,这样和数字相比更容易辨识,不容易出错。命名分组的格式为:(?P<分组名>正则)。
注意
命名分组只有部分编程语言才支持。
# 分组引用
大部分情况下,我们可以使用 “反斜扛 + 编号”,即 \number 的方式来进行引用,而 JavaScript 中是通过 $number 来引用的,如 $1。
// 查找重复的单词
(\w+)\1
// 替换日期格式
((\d{4})-(\d{2})-(\d{2})) ((\d{2}):(\d{2}):(\d{2})) // 匹配到的时间格式如:2023-03-17 18:00:00
日期\1 时间\5 \2年\3月\4日 \6时\7分\8秒 // 替换后的结果为:日期2023-03-17 时间18:00:00 2023年03月17日 18时00分00秒
2
3
4
5
6
# 断言
在实际使用正则的过程中,\d{11} 能匹配上 11 位数字,但这 11 位数字可能是 18 位身份证号中的一部分。再比如,去查找一个单词,我们要查找 tom,但其它的单词,比如 tomorrow 中也包含了 tom。
在有些情况下,我们对要匹配的文本的位置会有一定的要求。为了解决这个问题,正则中提供了一些结构,只用于匹配位置,而不是文本内容本身,这种结构就是断言。
常见的断言有三种:单词边界、行的开始或结束以及环视。
# 转义
转义序列通常有两种功能。第一种功能是编码无法用字母表直接表示的特殊数据。第二种功能是用于表示无法直接键盘录入的字符(如回车符)。
# Unicode 正则
# Unicode 基础知识
Unicode 是计算机科学领域里的一项业界标准。它对世界上大部分的文字进行了整理、编码。Unicode 使计算机呈现和处理文字变得简单。
现有的 Unicode 字符分为 17 个平面,每组为一个平面(Plane),而每个平面拥有 65536(即 2 的 16 次方)个码值。然而,目前 Unicode 只用了少数平面,我们用到的绝大多数字符都属于第 0 号平面(U+0000-U+FFFF),即 BMP 平面。除了 BMP 平面之外,其它的平面都被称为补充平面。
Unicode 相当于规定了字符对应的码值,这个码值得编码成字节的形式去传输和存储。
最常见的编码方式是 UTF-8,另外还有 UTF-16,UTF-32 等。
UTF-8 之所以能够流行起来,是因为其编码比较巧妙,采用的是变长的方法。也就是一个 Unicode 字符,在使用 UTF-8 编码表示时占用 1 到 4 个字节不等。最重要的是 Unicode 兼容 ASCII 编码,在表示纯英文时,并不会占用更多存储空间。而汉字在 UTF-8 中,通常是用三个字节来表示。
# Unicode 中的正则
在编程语言中使用正则时,一定尽可能地使用 Unicode 编码。
在 Unicode 中,点号以及字符组,比如:\d、\w、\s 等等是否可以匹配上 Unicode 字符,不同语言支持的不太一样,具体需要通过测试来得知。
# Unicode 属性
在正则中使用 Unicode,还可能会用到 Unicode 的一些属性。这些属性把 Unicode 字符集划分成不同的字符小集合。常用的有三种:
按功能划分的 Unicode Categories(也叫 Unicode Properties),比如标点、数字、空白符等,示例:\p{P} 表示标点符号,\p{N} 表示数字字符;
连续区间划分的 Unicode Blocks,比如只是中日韩字符,示例:\p{Arrows} 表示箭头符号,\p{Bopomofo} 表示注音字母;
按书写系统划分的 Unicode Scripts,比如汉语中文字符,示例:\p{Han} 表示汉语。
注意
不同编程语言对这些 Unicode 属性的支持和使用也有差异。
# 表情符号
表情符号有如下特点:
许多表情不在 BMP 内,码值超过了 FFFF。使用 UTF-8 编码时,普通的 ASCII 是 1 个字节,中文是 3 个字节,而有一些表情需要 4 个字节来编码。
这些表情分散在 BMP 和各个补充平面中,要想用一个正则来表示所有的表情符号非常麻烦,即便使用编程语言处理也同样很麻烦。
一些表情现在支持使用颜色修饰,可以在 5 种色调之间进行选择。这样一个表情其实就是 8 个字节了。
因此,表情符号不建议使用正则来处理,更建议使用专用的表情库来处理。
# 在 JS 中使用正则
# 校验文本内容
在 JavaScript 中没有 \A 和 \z,我们可以使用 ^ 和 $ 来表示每行的开头和结尾,默认情况下它们是匹配整个文本的开头或结尾(默认不是多行匹配模式)。
在 JavaScript 中校验文本的时候,不要使用多行匹配模式,因为使用多行模式会改变 ^ 和 $ 的匹配行为。
// 方法 1
/^\d{4}-\d{2}-\d{2}$/.test("2020-06-01") // true
// 方法 2
var regex = /^\d{4}-\d{2}-\d{2}$/
"2020-06-01".search(regex) === 0 // true
// 方法 3
var regex = new RegExp(/^\d{4}-\d{2}-\d{2}$/)
regex.test("2020-01-01") // true
2
3
4
5
6
7
8
9
10
方法 3 本质上和方法 1 是一样的,方法 1 写起来更简洁。
需要注意的是,在使用 RegExp 对象时,如果使用 g 模式,可能会有意想不到的结果,连续调用会出现第二次返回 false 的情况。比如:
var r = new RegExp(/^\d{4}-\d{2}-\d{2}$/, "g")
r.test("2020-01-01") // true
r.test("2020-01-01") // false
2
3
这是因为 RegExp 在全局模式下,正则会找出文本中的所有可能的匹配,找到一个匹配时会记下 lastIndex,在下次再查找时找不到,lastIndex 变为 0,所以才有上面现象。
var regex = new RegExp(/^\d{4}-\d{2}-\d{2}$/, "g")
regex.test("2020-01-01") // true
regex.lastIndex // 10
regex.test("2020-01-01") // false
regex.lastIndex // 0
// 为了加深理解,还可以看下面这个例子
var regex = new RegExp(/\d{4}-\d{2}-\d{2}/, "g")
regex.test("2020-01-01 2020-02-02") // true
regex.lastIndex // 10
regex.test("2020-01-01 2020-02-02") // true
regex.lastIndex // 21
regex.test("2020-01-01 2020-02-02") // false
2
3
4
5
6
7
8
9
10
11
12
13
因此要记住,JavaScript 中文本校验在使用 RegExp 时不要设置 g 模式。
此外,在 ES6 中添加了匹配模式 u,如果要在 JavaScript 中匹配中文等多字节的 Unicode 字符,可以指定匹配模式 u,比如测试是否为一个字符,可以是任意 Unicode 字符。𝌆 (opens new window)
/^\u{1D306}$/u.test("𝌆") // true
/^\u{1D306}$/.test("𝌆") // false
/^.$/u.test("好") // true
/^.$/u.test("好人") // false
/^.$/u.test("a") // true
/^.$/u.test("ab") // false
2
3
4
5
6
# 提取文本内容
所谓内容提取,就是从大段的文本中抽取出我们关心的内容。比较常见的例子是网页爬虫,或者说从页面上提取邮箱、抓取需要的内容等。
如果要抓取的是某一个网站,页面样式是一样的,要提取的内容都在同一个位置,可以使用 xpath 或 jquery 选择器等方式,否则就只能使用正则来做了。
在 JavaScript 中,想要提取文本中所有符合要求的内容,正则必须使用 g 模式,否则找到第一个结果后,正则就不会继续向后查找了。
// 使用 g 模式,查找所有符合要求的内容
"2020-06 2020-07".match(/\d{4}-\d{2}/g) // 输出:["2020-06", "2020-07"]
// 不使用 g 模式,找到第一个就会停下来
"2020-06 2020-07".match(/\d{4}-\d{2}/) // 输出:["2020-06", index: 0, input: "2020-06 2020-07", groups: undefined]
2
3
4
5
如果要查找中文等 Unicode 字符,可以使用 u 匹配模式。
'𝌆'.match(/\u{1D306}/ug) // 使用匹配模式 u,𝌆
'𝌆'.match(/\u{1D306}/g) // 不使用匹配模式 u,null
2
# 替换文本内容
在 JavaScript 中替换和查找类似,需要指定 g 模式,否则只会替换第一个。
// 使用 g 模式,替换所有的
"02-20-2020 05-21-2020".replace(/(\d{2})-(\d{2})-(\d{4})/g, "$3年$1月$2日")
// 输出 "2020年02月20日 2020年05月21日"
// 不使用 g 模式,只替换一次
"02-20-2020 05-21-2020".replace(/(\d{2})-(\d{2})-(\d{4})/, "$3年$1月$2日")
// 输出 "2020年02月20日 05-21-2020"
2
3
4
5
6
7
# 切割文本内容
"apple, pear! orange; tea".split(/\W+/) // 输出:["apple", "pear", "orange", "tea"]
// 传入第二个参数的情况
"apple, pear! orange; tea".split(/\W+/, 1) // 输出:["apple"]
"apple, pear! orange; tea".split(/\W+/, 2) // 输出:["apple", "pear"]
"apple, pear! orange; tea".split(/\W+/, 10) // 输出:["apple", "pear", "orange", "tea"]
2
3
4
5
6
# 正则匹配原理
# 有穷状态自动机
有穷状态是指一个系统具有有穷个状态,不同的状态代表不同的意义。
自动机是指系统可以根据相应的条件,在不同的状态下进行转移。从一个初始状态,根据对应的操作(比如录入的字符集)执行状态转移,最终达到终止状态(可能有一到多个终止状态)。
正则引擎的具体实现就是有穷状态自动机。主要有 DFA(确定性有穷自动机)和 NFA(非确定性有穷自动机)两种,其中 NFA 又分为传统的 NFA 和 POSIX NFA。
NFA 和 DFA 是可以相互转化的。
# DFA 和 NFA 的工作机制
NFA 是以正则为主导,先看正则,再看文本。
DFA 则是以文本为主导,先看文本,再看正则。
一般来说,DFA 引擎会更快一些,因为整个匹配过程中,字符串只看一遍,不会发生回溯,相同的字符不会被测试两次。也就是说 DFA 引擎执行的时间一般是线性的。DFA 引擎可以确保匹配到可能的最长字符串。但由于 DFA 引擎只包含有限的状态,所以它没有反向引用功能;并且因为它不构造显示扩展,它也不支持捕获子组。
NFA 以正则为主导,它的引擎是使用贪心匹配回溯算法实现。NFA 通过构造特定扩展,支持子组和反向引用。但由于 NFA 引擎会发生回溯,即它会对字符串中的同一部分,进行很多次对比。因此,在最坏情况下,它的执行速度可能非常慢。
回溯是 NFA 引擎才有的,并且只有在正则中出现量词或多选分支结构时,才可能会发生回溯。
# POSIX NFA 和传统 NFA 的区别
传统的 NFA 引擎 “急于” 报告匹配结果,找到第一个匹配上的就返回了,所以可能会导致还有更长的匹配未被发现。
POSIX NFA 的应用很少,主要是 Unix/Linux 中的某些工具。POSIX NFA 在找到可能的最长匹配之前会继续回溯,也就是说它会尽可能找最长的,如果分支一样长,以最左边的为准。因此,POSIX NFA 引擎的速度要慢于传统的 NFA 引擎。
我们日常接触的一般都是传统的 NFA,所以通常都是最左侧的分支优先,在书写正则的时候务必要注意这一点。
# 正则优化建议
必须先保证正则的功能是正确的,然后再进行优化性能。
# 测试性能的方法
可以在 regex101 (opens new window) 上查看正则和文本匹配的次数,来得知正则的性能信息。
# 提前编译好正则
编程语言中一般都有 “编译” 方法,我们可以使用这个方法提前将正则处理好,这样不用在每次使用的时候去反复构造自动机,从而可以提高正则匹配的性能。
# 尽量准确表示匹配范围
比如我们要匹配引号里面的内容,除了写成 .+? 之外,还可以写成 [^"]+。使用 [^"] 要比使用点号好很多,虽然使用的是贪婪模式,但它不会出现点号将引号匹配上,再吐出的问题。
# 提取出公共部分
类似 abcd|abxy 这样的表达式,可以优化成 ab(cd|xy),因为 NFA 以正则为主导,会导致字符串中的某些部分重复匹配多次,影响效率。
因此 th(?:is|at) 要比 this|that 要快一些,但从可读性上看,后者要好一些,这个就需要用的时候去权衡,也可以添加代码注释让代码更容易理解。
如果是锚点,比如 (^this|^that)is 这样的,锚点部分也应该独立出来,可以写成比如 ^th(is|at)is 的形式,因为锚点部分也是需要尝试去匹配的,匹配次数要尽可能少。
# 出现可能性大的放左边
由于正则是从左到右看的,把出现概率大的放左边。比如域名中 .com 的使用是比 .net 多的,所以我们可以写成 .(?:com|net)\b 而不是 .(?:net|com)\b。
# 只在必要时才使用子组
在正则中,括号可以用于归组,但如果某部分后续不会再用到,就不需要保存成子组。
通常的做法是,在写好正则后,把不需要保存子组的括号中加上 ?: 来表示只用于归组。如果保存成子组,正则引擎必须做一些额外工作来保存匹配到的内容,因为后面可能会用到,这会降低正则的匹配性能。
# 警惕嵌套的子组重复
如果一个组里面包含重复,接着这个组整体也可以重复,比如 (.*)* 这个正则,匹配的次数会呈指数级增长,所以尽量不要写这样的正则。
# 避免不同分支重复匹配
在多选分支选择中,要避免不同分支出现相同范围的情况。
# 使用正则处理问题的思路
将问题分解成多个小问题,每个小问题见招拆招:
某个位置上可能有多个字符的话,就⽤字符组。
某个位置上有多个字符串的话,就⽤多选结构。
出现的次数不确定的话,就⽤量词。
对出现的位置有要求的话,就⽤锚点锁定位置。
在正则中比较难的是某些字符不能出现,这个情况又可以进一步分为组成中不能出现,和要查找的内容前后不能出现。
后一种用环视来解决就可以了。至于第一种:
如果是要查找的内容中不能出现某些字符,这种情况比较简单,可以通过使用中括号来排除字符组,比如非元音字母可以使用 [^aeiou] 来表示。
如果是内容中不能出现某个子串,比如要求密码是 6 位,且不能有连续两个数字出现。这个可以环视来解决,就是每个字符的后面都不能是 两个数字(要注意开头也不能是 \d\d)。
^((?!\d\d)\w){6}$
# 正则工具
# 正则资料
← 代理模式 时间复杂度和空间复杂度 →